
Un chatbot médical affirme avec aplomb qu’un médicament interagit dangereusement avec un autre, alors qu’aucune étude clinique ne le confirme. Un assistant juridique cite un arrêt de tribunal qui n’a jamais existé, en donnant numéro de pourvoi et date. Le modèle ne s’est pas « planté » au sens classique : il a fabriqué de toute pièce une information fausse en la présentant avec le même ton assuré que n’importe quel fait vérifié. Ce phénomène, qu’on appelle hallucination, constitue le problème central de fiabilité de toute l’IA générative.
Les hallucinations : des erreurs qui ne ressemblent pas à des erreurs
Une hallucination, dans le contexte des modèles de langage (les LLM, pour large language model, ces systèmes entraînés à prédire le mot suivant dans un texte), désigne une réponse générée qui est incorrecte, nonsensique ou entièrement inventée [1]. Contrairement à un bug logiciel classique, le modèle ne s’arrête pas, ne plante pas, ne renvoie pas de message d’erreur. Il continue de produire du texte fluide, structuré, convaincant.
Ces hallucinations prennent plusieurs formes. Le modèle peut :
- Inventer des faits : affirmer qu’un événement historique a eu lieu alors qu’il n’a jamais existé, ou attribuer des propriétés pharmacologiques sans aucun fondement.
- Fabriquer des sources : citer un article scientifique avec auteur, titre et date, mais dont aucune trace n’existe dans aucune base de données.
- Raisonner de façon cohérente sur des prémisses fausses : le fil logique est impeccable, mais il part d’une prémisse inventée, ce qui rend le résultat d’autant plus trompeur.
- Générer des incohérences internes : affirmer dans la même phrase deux choses contradictoires, comme « Daniele est grand, c’est donc la personne la plus petite de la pièce » [2].
Ce qui rend ces erreurs particulièrement dangereuses, c’est précisément leur fluidité. Les LLM produisent des réponses claires, bien articulées et motivées, même lorsqu’ils hallucinent [2]. Rien dans le ton ou la structure ne permet de distinguer d’emblée une réponse fiable d’une hallucination. Un utilisateur non averti n’a aucune raison de douter.
Pourquoi ça arrive : le modèle ne « sait » pas qu’il ne sait pas
Pour comprendre l’hallucination, il faut comprendre ce que fait réellement un LLM. Ce n’est pas une encyclopédie consultée par un moteur de recherche. C’est un modèle statistique qui a appris, pendant son entraînement sur des milliards de textes, à prédire le token (le morceau de mot) le plus probable suivant une séquence donnée. Quand il génère une réponse, il ne vérifie pas un savoir stocké quelque part : il calcule, à chaque étape, quel mot « colle » le mieux avec ce qui précède.
Deux conséquences structurelles découlent de cette architecture.
Le corpus d’entraînement est figé. Les modèles sont entraînés sur des données collectées à un moment donné et ne se mettent pas à jour d’eux-mêmes [3]. Si un événement survient après la date de collecte, le modèle ne le « connaît » pas. Plutôt que de dire « je ne sais pas », il va tenter de produire une réponse plausible en extrapolant à partir de patterns appris. C’est là que naissent les inventions.
Aucun mécanisme interne ne vérifie les faits. Le modèle n’a pas de module qui contrôle si ce qu’il dit est vrai. Il n’a pas accès à une base de connaissances structurée pendant la génération. Il n’a aucun « réflexe de doute » [3]. Son objectif unique est de maximiser la probabilité du prochain mot, pas de garantir la véracité de l’ensemble.
L’hallucination n’est pas un dysfonctionnement accidentel. C’est une conséquence directe de la façon dont ces modèles fonctionnent.
Quand l’alignement aggrave le paradoxe
On pourrait penser que les techniques d’alignement, c’est-à-dire les méthodes qui ajustent le comportement du modèle pour qu’il soit plus utile, plus sûr et plus proche des attentes humaines, réduiraient les hallucinations. La réalité est plus nuancée.
RAG & recherche documentaire : l'approche
Comment je le conçois concrètement : étapes, livrables et garde-fous.
Le RLHF (Reinforcement Learning from Human Feedback, apprentissage par renforcement à partir de retours humains) et le DPO (Direct Preference Optimization, optimisation directe des préférences) sont les deux principales techniques d’alignement utilisées aujourd’hui [31]. Elles fonctionnent en montrant au modèle des paires de réponses (une bonne, une moins bonne) et en l’entraînant à préférer celle que les évaluateurs humains ont jugée meilleure.
Le problème est que les évaluateurs humains tendent à préférer les réponses fluides, complètes et confiantes. Un « je ne sais pas » sera souvent noté moins favorablement qu’une réponse détaillée et bien formulée, même si cette dernière est partiellement inventée. Le modèle apprend donc à être confiant, y compris quand il ne devrait pas l’être.
Ce phénomène crée un paradoxe : plus un modèle est aligné sur les préférences humaines telles qu’exprimées dans le processus de RLHF, plus il peut devenir « séduisant et faux » simultanément [4][5]. Les techniques d’alignement améliorent la qualité perçue des réponses (fluidité, complétude, ton) tout en pouvant renforcer la confiance du modèle dans des affirmations non vérifiées.
En pratique, cela signifie qu’un modèle bien aligné n’est pas nécessairement un modèle plus véridique. La courtoisie et la précision factuelle sont deux axes distincts, et optimiser l’un peut dégrader l’autre.
RAG : ancrer la génération dans des faits vérifiables
Face à cette limite structurelle, la réponse la plus répandue aujourd’hui est le RAG (Retrieval-Augmented Generation, génération augmentée par la récupération). Le principe : avant de laisser le modèle générer une réponse, on lui fournit des passages pertinents extraits de sources externes fiables.
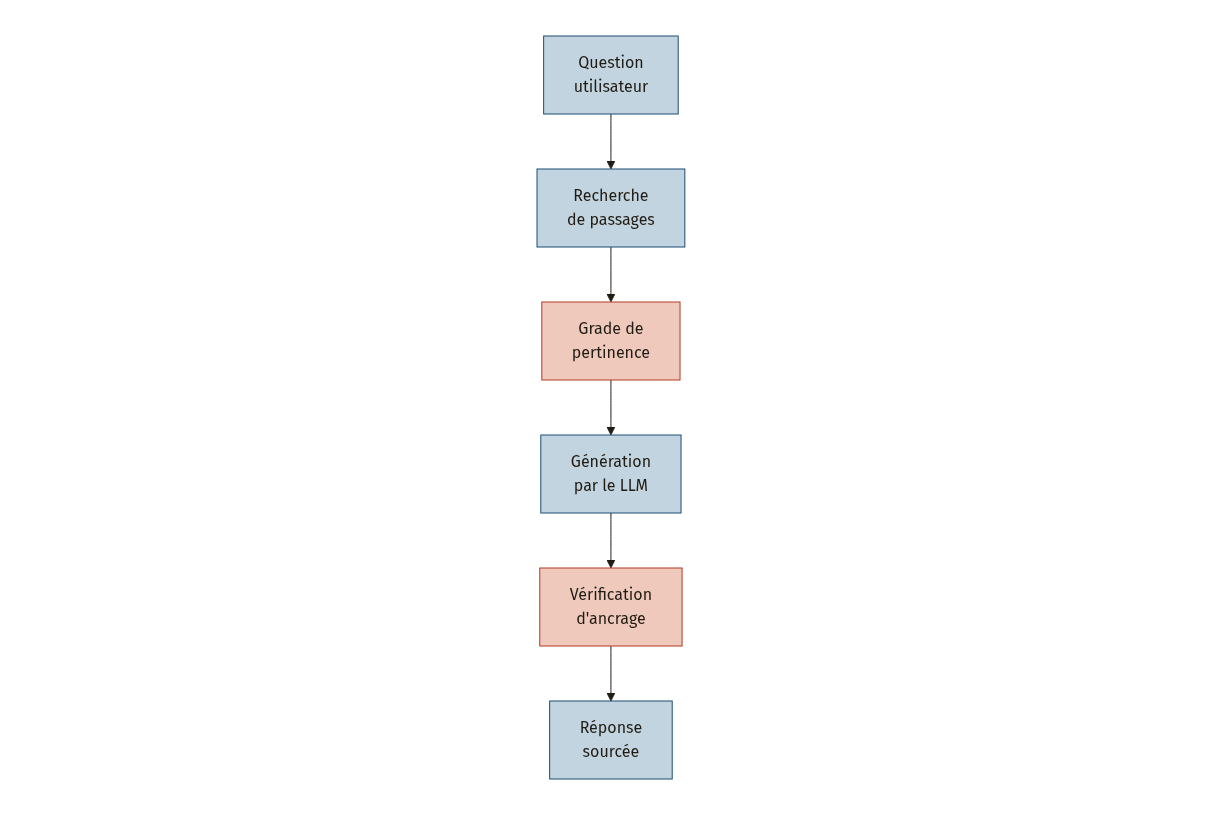
Le RAG a été proposé initialement pour combiner des retrieveurs denses (des systèmes qui cherchent des passages par similarité sémantique) avec des modèles génératifs, permettant au modèle de récupérer des passages de support au moment de la génération [3]. Le pipeline se décompose en trois étapes principales [6] :
- Chunking : découper les documents source en passages de taille gérable (les « chunks »).
- Retrieval : rechercher les chunks les plus pertinents par rapport à la question posée.
- Generation : laisser le LLM produire une réponse en s’appuyant sur les chunks récupérés.
Mais un RAG naïf, qui se contente de récupérer puis de générer, laisse passer beaucoup d’erreurs. Les systèmes fiables ajoutent des points de contrôle critiques entre chaque étape [7].
Trois garde-fous qui changent tout
Le grade de pertinence. Les chunks récupérés par la recherche vectorielle ne sont pas tous utiles. Un passage peut être sémantiquement proche de la question sans contenir la réponse. Le grading consiste à évaluer chaque chunk récupéré et à filtrer ceux qui ne sont pas réellement pertinents avant qu’ils n’atteignent le modèle [7]. Le système CRAG (Corrective RAG) va plus loin en intégrant un évaluateur léger qui attribue un degré de confiance à l’ensemble des documents récupérés et déclenche des actions correctives si ce degré est trop faible [8].
Le vérificateur d’hallucination. Même avec un excellent contexte, le LLM peut encore halluciner. Le modèle peut ignorer un passage pertinent, le mal interpréter, ou y ajouter des éléments inventés. Un hallucination checker vérifie que chaque affirmation de la réponse est effectivement soutenue par les faits fournis dans le contexte [7].
La traçabilité source. Chaque affirmation dans la réponse doit pouvoir être reliée à un passage précis dans les documents sources. Ce n’est pas seulement une question de transparence : c’est ce qui permet à l’utilisateur final de vérifier par lui-même [7].
Ne faites pas confiance aveuglément aux chunks récupérés. Évaluez-les. Ne faites pas confiance au modèle même avec un bon contexte. Vérifiez-le. Et exigez que chaque affirmation soit traçable.
La taille du contexte fourni au modèle joue aussi un rôle. Les expériences menées sur le benchmark BioASQ-QA et le dataset QuoteSum montrent que le nombre de passages fourni au modèle influence directement la qualité de la réponse [9]. Trop peu de passages, et le contexte est insuffisant. Trop, et le modèle subit une surcharge informationnelle qui dégrade ses performances, un phénomène observé notamment avec des approches comme IRCoT (Interleaving Retrieval with Chain-of-Thought), où l’accumulation de passages récupérés itérativement finit par nuire [10].
Au-delà du RAG : raisonner, structurer, hybrider
Le RAG est un socle indispensable, mais il ne suffit pas toujours, notamment pour les questions qui nécessitent un raisonnement en plusieurs étapes ou la mobilisation de connaissances dispersées dans plusieurs documents.
Le chain-of-thought : forcer la réflexion explicite
Le chain-of-thought prompting (l’incitation à la chaîne de pensée) demande au modèle de dérouler son raisonnement étape par étape avant de produire une réponse finale [11]. Au lieu de répondre directement, le modèle explique comment il parvient à sa conclusion. Ce processus explicite réduit les sauts logiques où le modèle « invente » un lien entre deux informations.
En pratique, le chain-of-thought est particulièrement efficace combiné au RAG : le modèle récupère des passages pertinents, puis raisonne explicitement sur ces passages. Des approches comme IRCoT entrelacent la récupération et le raisonnement, mais attention à la surcharge de contexte évoquée plus haut [10].
Les graphes de connaissances : structurer les relations
Le RAG traditionnel fonctionne sur du texte découpé en passages. Mais beaucoup de questions complexes reposent sur des relations entre entités (qui a inventé quoi, quel traitement agit sur quel récepteur, quelle entreprise appartient à quel groupe). Les knowledge graphs (les graphes de connaissances, des bases de données qui représentent l’information sous forme de nœuds et de liens) capturent ces relations de façon explicite.
Le GraphRAG étend le RAG classique en intégrant ces structures graphiques. Le benchmark GraphRAG-Bench a été développé pour évaluer précisément comment la structuration en graphe améliore les capacités de raisonnement des modèles. En testant neuf méthodes GraphRAG, il montre que les architectures graphiques apportent un gain mesurable sur les tâches de raisonnement complexe [12].
Le système MemGraphRAG pousse l’idée plus loin en combinant plusieurs agents (des sous-modèles spécialisés) avec une mémoire à long terme et un RAG basé sur le graphe, pour gérer des corpus massifs et non structurés où l’information est fragmentée [13].
La recherche hybride : ne rien laisser passer
La recherche vectorielle seule rate certains passages pertinents, notamment ceux qui utilisent des termes différents de la question mais contiennent la bonne information. La recherche lexicale (par mots-clés exacts, comme la recherche BM25) rate les passages qui reformulent la même idée avec d’autres mots.
La recherche hybride combine les deux approches pour récupérer à la fois les passages sémantiquement proches et ceux qui correspondent lexicographiquement [14]. Des approches comme AQE (Automatic Query Expansion) vont plus loin en générant automatiquement des requêtes élargies à partir de la question originale, réduisant le risque que le modèle hallucine faute d’avoir trouvé les bons passages [15].
Le reranking (le reclassement), qui réordonne les passages récupérés par pertinence décroissante grâce à un modèle spécialisé, complète le dispositif [14].
Détecter ce qui passe malgré tout
Même avec un RAG bien construit, du chain-of-thought et un graphe de connaissances, des hallucinations peuvent subsister. Il faut donc un dernier filet de sécurité : des systèmes de vérification en aval.
Un besoin en RAG & recherche documentaire ?
Configurez votre projet et recevez un devis clair sous 24h, sans engagement.
| Méthode | Fonctionnement | Ce qu’elle révèle |
|---|---|---|
| HHEM [14] | Classificateur entraîné, score entre 0 et 1 | La probabilité que la réponse soit ancrée dans les faits fournis |
| RefChecker [16] | Extraction de triplets de claims (affirmations) vérifiés un par un | Les hallucinations fines, affirmation par affirmation |
| Ragas faithfulness [17] | Un LLM-juge vérifie si chaque énoncé est soutenu par le contexte | Si oui, chaque phrase de la réponse est bien fondée dans les sources |
| DICE [18] | Évaluation explicable du système RAG complet | La fiabilité globale du pipeline, avec traçabilité des décisions |
Le HHEM (Hallucination Evaluation Model) est un modèle spécialisé qui agit comme un classificateur : on lui soumet une réponse et le contexte, et il retourne un score indiquant la probabilité que la réponse soit factuellement ancrée dans les informations fournies [14].
RefChecker adopte une approche plus granulaire : il décompose chaque réponse en triplets de claims et vérifie chaque claim individuellement par rapport au contexte [16]. C’est plus fin, mais aussi plus coûteux en temps de calcul.
Le framework Ragas propose une métrique de faithfulness (fidélité) qui utilise un LLM comme juge pour vérifier que chaque énoncé de la réponse est effectivement soutenu par le contexte fourni [17].
Le cadre DICE se concentre sur la fiabilité globale du pipeline en intégrant explicabilité, robustesse et efficacité [18]. Il ne se contente pas de vérifier la réponse finale : il évalue la chaîne complète, de la récupération à la génération.
La règle d’or : concevez votre système en partant du principe que le modèle va se tromper. Les garde-fous ne sont pas un luxe, ils sont la condition de déploiement.
Ce qui restera inévitable, et pourquoi c’est une question de design
Toutes les techniques présentées ici réduisent drastiquement les hallucinations. Aucune ne les élimine intégralement.
La raison fondamentale est simple : un modèle de langage reste un système probabiliste. Il génère du texte en calculant des probabilités sur chaque token, pas en consultant une vérité absolue [3]. Ce fonctionnement, qui lui donne sa flexibilité et sa créativité, est aussi ce qui empêche toute garantie de véracité à 100 %.
Les coupes temporelles dans les données d’entraînement créent des angles morts permanents : le modèle ne peut pas savoir ce qui s’est passé après la date de collecte de son corpus [3]. Les techniques d’alignement améliorent le comportement général mais peuvent renforcer la confiance dans des erreurs [4][5]. Même avec un contexte parfaitement pertinent, le modèle peut mal l’interpréter.
La bonne question n’est donc pas « comment éliminer toutes les hallucinations ? ». C’est « comment concevoir un système où les hallucinations qui passent sont détectées, contextualisées et jamais présentées comme des faits avérés ? ».
Concrètement, cela se traduit par une posture de confiance conditionnelle :
- Ne jamais présenter une réponse brute du modèle comme un fait. Toujours indiquer les sources et permettre la vérification.
- Implémenter les trois garde-fous du RAG fiable : grade de pertinence, vérification d’ancrage, traçabilité source [7].
- Prévoir des systèmes de détection en aval (HHEM, RefChecker, Ragas, DICE) comme filet de sécurité [14][18][16][17].
- Prévoir le cas où le modèle ne sait pas : mieux vaut un « je ne dispose pas d’assez d’informations pour répondre » qu’une hallucination convaincante.
- Documenter les limites de votre système pour que les utilisateurs sachent quoi attendre.
L’hallucination n’est pas un problème à résoudre une fois pour toutes. C’est un risque permanent à gérer, comme on gère tout risque dans un système critique : par des couches de vérification, une transparence sur les limites, et une conception qui assume que l’erreur est possible.
Sources
- [1] Building Applications with AI Agents Designing and Implementing Multiagent Systems · livre · Amazon
- [2] Generative AI on Kubernetes Operationalizing Large Language Models · livre · Amazon
- [3] Assessing RAG and HyDE on 1B vs. 4B-Parameter Gemma LLMs for Personal Assistants Integretion · Andrejs Sorstkins · 2025 · preprint · arXiv:2506.21568
- [4] TeaRAG: A Token-Efficient Agentic Retrieval-Augmented Generation Framework · Chao Zhang et al. · 2025 · preprint · arXiv:2511.05385
- [5] From Conflict to Consensus: Boosting Medical Reasoning via Multi-Round Agentic RAG · Wenhao Wu et al. · 2026 · preprint · arXiv:2603.03292
- [6] A Comprehensive Survey on Long Context Language Modeling · Jiaheng Liu et al. · 2025 · preprint · arXiv:2503.17407
- [7] RAG Made Simple: The Complete Visual Guide to Retrieval-Augmented Generation · Nir Diamant · livre · Amazon
- [8] Corrective Retrieval Augmented Generation · Shi-Qi Yan et al. · 2024 · preprint · arXiv:2401.15884
- [9] On the Influence of Context Size and Model Choice in Retrieval-Augmented Generation Systems · Juraj Vladika et al. · 2025 · preprint · arXiv:2502.14759
- [10] Retrieve, Summarize, Plan: Advancing Multi-hop Question Answering with an Iterative Approach · Zhouyu Jiang et al. · 2024 · preprint · arXiv:2407.13101
- [11] Right for Right Reasons: Large Language Models for Verifiable Commonsense Knowledge Graph Question Answering · Armin Toroghi et al. · 2024 · preprint · arXiv:2403.01390
- [12] GraphRAG-Bench: Challenging Domain-Specific Reasoning for Evaluating Graph Retrieval-Augmented Generation · Yilin Xiao et al. · 2025 · preprint · arXiv:2506.02404
- [13] MemGraphRAG: Memory-based Multi-Agent System for Graph Retrieval-Augmented Generation · Chuanjie Wu et al. · 2026 · preprint · arXiv:2606.00610
- [14] Hands-On RAG for Production · Ofer Mendelevitch and Forrest Sheng Bao · livre · Amazon
- [15] Aligned Query Expansion: Efficient Query Expansion for Information Retrieval through LLM Alignment · Adam Yang et al. · 2025 · preprint · arXiv:2507.11042
- [16] Towards Long Context Hallucination Detection · Siyi Liu et al. · 2025 · preprint · arXiv:2504.19457
- [17] RAG with Python Cookbook Practical Recipes from Data Preprocessing to LLM Agents · livre · Amazon
- [18] DICE: Discrete Interpretable Comparative Evaluation with Probabilistic Scoring for Retrieval-Augmented Generation · Shiyan Liu et al. · 2025 · preprint · arXiv:2512.22629


