Quand vous demandez à un modèle de langage « combien font 27 × 48 ? », il peut répondre instantanément… et se tromper. Demandez-lui en revanche de décomposer le calcul en étapes (dizaines, unités, retenue), et la justesse s’améliore nettement. Cette observation, formalisée dans l’étude fondatrice sur le chain-of-thought prompting [1], est devenue l’une des techniques les plus influentes pour extraire un raisonnement fiable d’un LLM.
Qu’est-ce que le Chain-of-Thought ?
Un grand modèle de langage (LLM) s’appuie sur l’apprentissage en contexte : sa capacité à s’adapter à des tâches nouvelles grâce au seul texte du prompt, sans modifier ses paramètres internes [2]. Le chain-of-thought (CoT) prompting pousse cette capacité un cran plus loin en invitant explicitement le modèle à produire des étapes de raisonnement intermédiaires avant d’aboutir à sa réponse finale [2].
Concrètement, au lieu de formuler une question qui attend une réponse directe, on ajoute au prompt une instruction du type « raisonne étape par étape ». Le modèle décompose alors le problème en sous-problèmes gérables, chacun traité séquentiellement [3]. Cette approche brille sur les tâches qui exigent un raisonnement logique, des calculs à plusieurs étapes ou une prise de décision multi-facteurs : résolution de problèmes mathématiques, analyse de scénarios complexes, réponse à des questions nécessitant de chaîner plusieurs faits [3].
L’effet est mesurable. Sur des benchmarks de problèmes mathématiques formulés en langage naturel, le CoT prompting améliore significativement la précision par rapport au prompting direct [1][141]. L’explication tient en un mot : la granularité. Un calcul mental de trois opérations enchaînées est difficile ; trois opérations élémentaires isolées sont triviales. Le CoT transfère cette logique au modèle.
Trois variantes à maîtriser : zéro exemple, quelques exemples, décomposition
Le CoT ne se limite pas à « pense étape par étape ». Il existe plusieurs variantes, chacune adaptée à un niveau de complexité et à un contexte différents.
| Variante | Ce qu’on écrit dans le prompt | Quand l’utiliser |
|---|---|---|
| Zero-shot CoT | « Let’s think step by step » ou « Raisonne étape par étape » [4] | Complexité modérée, aucun exemple disponible. Le signal de raisonnement seul suffit à orienter le modèle. |
| Few-shot CoT | Exemples annotés montrant la question, les étapes intermédiaires et la réponse [4][3] | Tâches complexes ou spécialisées où le modèle doit voir la structure de raisonnement attendue. |
| Thread of Thought (ThoT) | « Walk me through the problem in manageable parts, summarizing and analyzing as you go » [4] | Contextes longs ou multi-tours (dialogues, documents) où il faut maintenir le fil conducteur. |
| Décomposition | Instruction explicite de découper la tâche en sous-tâches distinctes [4] | Problèmes composites où chaque sous-problème peut être résolu indépendamment avant d’être synthétisé. |
Templates prêts à l’emploi. Pour le zero-shot CoT, la formulation la plus éprouvée reste « Let’s think step by step » [4], à placer après l’énoncé du problème. Pour le few-shot, on présente deux à cinq exemples complets illustrant le raisonnement attendu, puis on pose la question cible dans le même format [3][5] :
Question : Un magasin a 7 pommes et en reçoit 2. Combien en a-t-il ?
Raisonnement : 7 pommes de départ + 2 reçues = 9.
Réponse : 9.
Question : [votre question ici]
Une variante utile, le Rephrase and Respond (RaR), consiste à demander au modèle de reformuler et d’étendre la question avant d’y répondre [5]. Le modèle clarifie ainsi les ambiguïtés de la question initiale avant de s’engager dans le raisonnement.
Le critère de choix se résume simplement : tâche simple sans exemple à portée de main → zero-shot CoT. Tâche complexe ou domaine spécialisé → few-shot CoT avec exemples annotés. Contexte long ou multi-tour → Thread of Thought. Problème composite → décomposition en sous-tâches.
Quand CoT échoue : trop penser, mal penser
Le CoT n’est pas un remède universel. Trois écueils documentés méritent votre attention avant de l’adopter.
Intégration d'IA : l'approche
Comment je le conçois concrètement : étapes, livrables et garde-fous.
L’overthinking : quand le raisonnement paralyse l’action. Dans les tâches agenciales, où le modèle doit non seulement raisonner mais aussi agir (appeler des outils, interagir avec un environnement), un raisonnement excessif devient contre-productif. L’étude sur le dilemme raisonnement-action dans les tâches agenciales [142] documente ce phénomène : le modèle se perd dans des scénarios hypothétiques au lieu de passer à l’acte. C’est la paralysie par l’analyse, appliquée aux LLM.
La sensibilité aux inputs parasites. Les modèles de langage sont vulnérables aux informations non pertinentes glissées dans le contexte, et le CoT ne les en protège pas automatiquement [62]. Si votre prompt contient des données hors sujet ou contradictoires, le modèle peut construire une chaîne de raisonnement parfaitement logique… mais fondée sur de mauvaises prémisses. La rigueur formelle du raisonnement ne garantit pas la pertinence des faits sur lesquels il s’appuie.
Les connaissances gelées et l’hallucination persistante. Les connaissances paramétriques d’un LLM (ce qu’il a appris pendant son entraînement) sont figées à la date de son dernier entraînement [2]. Le CoT ne change rien à cette contrainte : même en raisonnant étape par étape, le modèle peut halluciner des faits, en particulier sur des sujets récents ou de niche [2]. Demander à un modèle entraîné jusqu’en 2023 de raisonner sur un événement de 2025 produira une chaîne de raisonnement convaincante… mais potentiellement fictive.
Plus de tokens ne veut pas dire meilleur raisonnement. L’étude « Same task, more tokens » [6] met en garde sur ce point : allonger la chaîne de raisonnement (plus d’étapes, plus de détails) n’améliore pas automatiquement la qualité de la réponse. Au-delà d’un certain seuil, les étapes supplémentaires introduisent du bruit. L’objectif n’est pas de maximiser la longueur du raisonnement, mais de le calibrer à la complexité réelle du problème.
Intégrer CoT dans un système réel : RAG, graphes de connaissances, outils
En production, le CoT fonctionne rarement seul. Il s’insère dans une architecture plus large qui combine raisonnement, récupération de connaissances et appels d’outils. Le principe directeur : le raisonnement CoT devient la boucle centrale du système, et à chaque étape, le modèle décide s’il dispose de suffisamment d’informations ou s’il doit chercher de l’aide à l’extérieur.
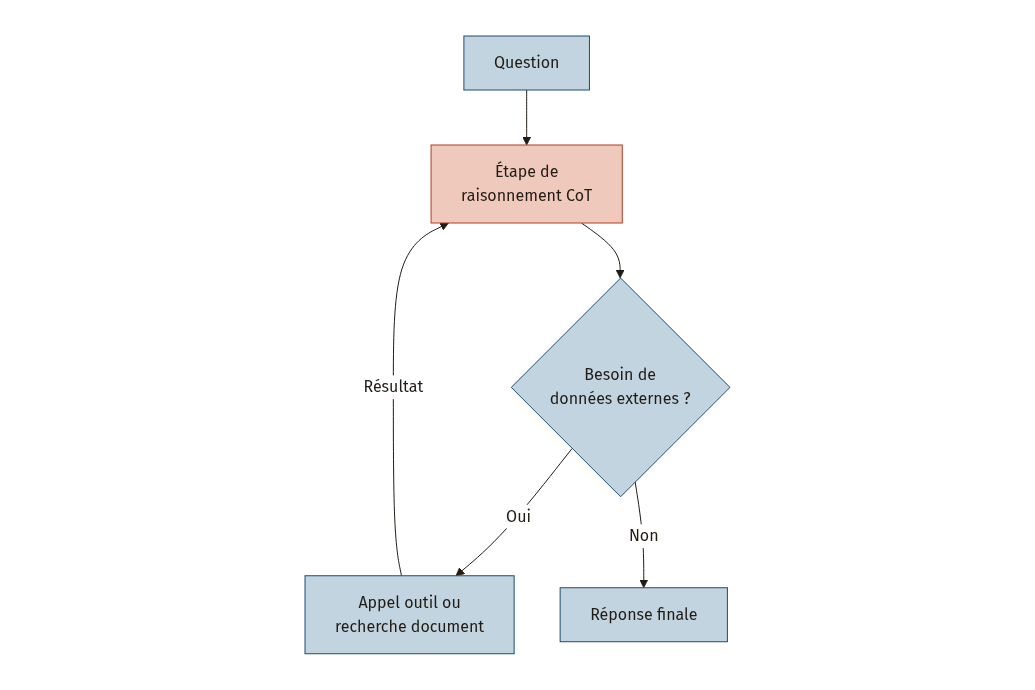
Avec le RAG (Retrieval-Augmented Generation, récupération augmentée par génération). Dans une architecture RAG, le modèle interroge une base de documents pour compléter ses connaissances. L’étude Fine-Tuning vs. RAG for Multi-Hop Question Answering [7] montre que le CoT combiné au retrieval est particulièrement efficace pour les questions multi-hop, celles qui nécessitent de chaîner plusieurs informations issues de sources différentes. Le modèle raisonne en étapes, et à chaque étape, il peut décider de chercher un document complémentaire avant de poursuivre.
Avec les graphes de connaissances (KG). Le framework Think-on-Graph [8] intègre le raisonnement CoT directement dans la traversée d’un graphe de connaissances : le modèle avance de nœud en nœud, raisonnant à chaque étape sur les relations pertinentes. Ce couplage est précieux car les LLM seuls peinent à naviguer dans des structures relationnelles complexes. Pour les modèles de petite taille, des modules d’exploration dédiés peuvent prendre en charge la traversée du graphe à la place du modèle [9], libérant ainsi sa capacité de raisonnement pour l’analyse sémantique.
Avec les outils via MCP. Le Model Context Protocol (MCP) standardise la manière dont un LLM interagit avec des outils externes : il définit une interface cohérente pour découvrir les outils disponibles, les invoquer avec des entrées structurées, et réintégrer les résultats dans le raisonnement [10]. Dans ce cadre, le CoT sert de boussole : c’est lui qui détermine, à chaque étape, quel outil appeler et comment interpréter sa réponse.
L’erreur classique à éviter : construire un pipeline où le CoT s’exécute une seule fois, en amont, sans boucle de rétroaction. Les architectures les plus performantes laissent le modèle revenir à sa chaîne de raisonnement après chaque appel d’outil, affinant son analyse à chaque itération. Le CoT n’est pas une préparation, c’est le moteur continu du système.
Faire raisonner les petits modèles : distillation et tokens continus
Exécuter un CoT long sur un LLM de 70 milliards de paramètres est coûteux en temps et en calcul. Deux approches permettent de transférer les capacités de raisonnement vers des modèles plus compacts.
Un besoin en intégration d'IA ?
Configurez votre projet et recevez un devis clair sous 24h, sans engagement.
La distillation de chaînes de raisonnement. Le principe est direct : un grand modèle génère des chaînes de raisonnement détaillées, qui servent ensuite de données d’entraînement pour un petit modèle. L’étude Orca 2 [11] a montré que des modèles compacts peuvent apprendre à raisonner efficacement en s’entraînant sur les traces de raisonnement de modèles plus grands. Aujourd’hui, des modèles comme DeepSeek-R1-Distill-Llama-8B [12] incarnent cette approche : huit milliards de paramètres, distillé à partir d’un raisonneur puissant, capable de produire des chaînes de CoT de qualité. En pratique, l’entraînement minimise l’écart entre les distributions de sortie du modèle enseignant et de l’élève, complété par un fine-tuning sur les solutions générées [12]. Des techniques de compression progressive des chaînes permettent d’entraîner le modèle sur des solutions de plus en plus concises, optimisant le rapport qualité/coût [12].
Le résultat est concret. L’étude TraceLLM montre que des modèles légers, associés à des prompts soigneusement conçus, peuvent égaler voire dépasser la performance de modèles plus grands, offrant une alternative rentable pour le déploiement en production [13].
Le SoftCoT : raisonner en espace continu. Au lieu de produire des étapes de raisonnement sous forme de texte (une chaîne de mots), le framework SoftCoT [14] génère des « tokens de pensée souples » : des vecteurs continus qui encodent l’information de raisonnement sans passer par la génération de texte explicite. Le modèle apprend à produire ces vecteurs à partir de l’entrée, via un module de génération inspiré du prompt tuning (technique où l’on entraîne de petits vecteurs de contexte plutôt que le modèle entier) [14].
L’architecture SoftCoT comporte trois composants [14] : un module de génération de tokens de pensée souples, un module de projection qui les adapte à l’espace du modèle cible, et un module de raisonnement CoT qui les intègre pour produire la réponse. L’intérêt est double : le raisonnement se produit en espace continu, ce qui est plus expressif que le texte discret, et le coût d’inférence diminue puisqu’on ne génère pas de longues chaînes de mots.
CoT comme fondation des modèles de raisonnement et des agents
Le CoT prompting ne reste pas une simple technique de prompt. Il est devenu la pierre angulaire d’une nouvelle catégorie de modèles et d’architectures, ce qui change la donne pour tout praticien.
Les modèles de raisonnement dédiés. La famille de modèles o1 d’OpenAI a démontré des performances significativement améliorées sur les tâches de mathématiques, de logique et de programmation [15]. Google a suivi avec Gemini Flash Thinking, DeepSeek avec R1 [15]. Dans la communauté open-source, une vague d’activité a émergé autour de la reproduction de ces capacités, de la calibration de la confiance, et des capacités agenciales avec des traces de raisonnement explicites [15]. L’étude comparative sur les patterns de raisonnement du modèle o1 [61] révèle que ces modèles intègrent le raisonnement en étapes de façon native : ils produisent spontanément des chaînes de pensée structurées, sans qu’il soit nécessaire de l’induire par un prompt CoT explicite. Pour le praticien, cela signifie que le choix du modèle peut se substituer au choix du prompt.
La vérification : outcome vs. process. Pour fiabiliser les chaînes de raisonnement, deux paradigmes s’affrontent. L’évaluation par le résultat (outcome-based) ne juge que la réponse finale ; l’évaluation par le processus (process-based) vérifie chaque étape intermédiaire. L’étude Training Verifiers to Solve Math Word Problems [141] a posé les bases de l’approche outcome-based en entraînant des modèles capables de distinguer les bonnes réponses des mauvaises parmi plusieurs tentatives. Plus récemment, le framework Process Reinforcement through Implicit Rewards [143] explore des récompenses implicites pour évaluer chaque étape de la chaîne individuellement. L’enjeu est considérable : le process reward permet de détecter une erreur logique même lorsque la réponse finale est accidentellement correcte, améliorant la robustesse globale.
L’agent autonome et le curseur raisonnement-action. Dans une architecture agentique, le CoT fait partie d’un cycle où le modèle alterne entre réflexion et action. Le risque documenté est double : passer trop de temps à raisonner et pas assez à agir, ou l’inverse [142]. La conception d’un agent performant exige de calibrer ce curseur, par exemple en limitant le nombre d’étapes de raisonnement avant une action forcée, ou en définissant des conditions de déclenchement qui contraignent le passage à l’acte après un seuil de réflexion atteint.
Ce que le CoT laisse ouvert. Le mécanisme entropique du renforcement appliqué au raisonnement [144] explore comment la diversité des chaînes de raisonnement affecte la qualité des réponses. Trop de diversité produit du bruit ; trop peu enferme le modèle dans des schémas rigides. Cette tension reste non résolue. Pour le praticien, l’enseignement est concret : ne cherchez pas un prompt CoT unique et figé. Testez plusieurs formulations sur vos cas d’usage réels, mesurez la qualité des réponses, et ajustez le niveau de détail du raisonnement en fonction de la complexité de vos problèmes. Le bon prompt CoT est celui que vous avez calibré, pas celui que vous avez copié.
Sources
- [1] Generate-then-Ground in Retrieval-Augmented Generation for Multi-hop Question Answering · Zhengliang Shi et al. · 2024 · preprint · arXiv:2406.14891
- [2] SoK: Agentic Retrieval-Augmented Generation (RAG): Taxonomy, Architectures, Evaluation, and Research Directions · Saroj Mishra et al. · 2026 · preprint · arXiv:2603.07379
- [3] LLMOps Managing Large Language Models in Production · livre · Amazon
- [4] Building Generative AI Services with FastAPI A Practical Approach to Developing Context-Rich Generative AI Applications · livre · Amazon
- [5] Generative Query Expansion with Multilingual LLMs for Cross-Lingual Information Retrieval · Olivia Macmillan-Scott et al. · 2025 · preprint · arXiv:2511.19325
- [6] Is It Really Long Context if All You Need Is Retrieval? Towards Genuinely Difficult Long Context NLP · Omer Goldman et al. · 2024 · preprint · arXiv:2407.00402
- [7] Fine-Tuning vs. RAG for Multi-Hop Question Answering with Novel Knowledge · Zhuoyi Yang et al. · 2026 · preprint · arXiv:2601.07054
- [8] Question-guided Knowledge Graph Re-scoring and Injection for Knowledge Graph Question Answering · Yu Zhang et al. · 2024 · preprint · arXiv:2410.01401
- [9] The Role of Exploration Modules in Small Language Models for Knowledge Graph Question Answering · Yi-Jie Cheng et al. · 2025 · preprint · arXiv:2509.07399
- [10] Hands-On LLM Serving and Optimization Hosting LLMs at Scale · livre · Amazon
- [11] GroUSE: A Benchmark to Evaluate Evaluators in Grounded Question Answering · Sacha Muller et al. · 2024 · preprint · arXiv:2409.06595
- [12] CoT-Valve: Length-Compressible Chain-of-Thought Tuning · Xinyin Ma et al. · 2025 · preprint · arXiv:2502.09601
- [13] TraceLLM: Leveraging Large Language Models with Prompt Engineering for Enhanced Requirements Traceability · Nouf Alturayeif et al. · 2026 · preprint · arXiv:2602.01253
- [14] SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs · Yige Xu et al. · 2025 · preprint · arXiv:2502.12134
- [15] Rank-K: Test-Time Reasoning for Listwise Reranking · Eugene Yang et al. · 2025 · preprint · arXiv:2505.14432


