
Brancher un LLM sur une base documentaire et espérer que la magie opère : c’est le piège le plus courant. Un prototype de RAG fonctionnel se monte en une après-midi. Un RAG fiable, scalable, qui résiste aux requêtes complexes et aux données sales de la vraie vie, c’est un projet d’ingénierie complet. Ce qui suit décrit chaque couche de ce projet, de la première ligne de parsing jusqu’au système capable de s’auto-corriger en production.
1. Avant le premier vecteur : ingérer, nettoyer et découper vos données
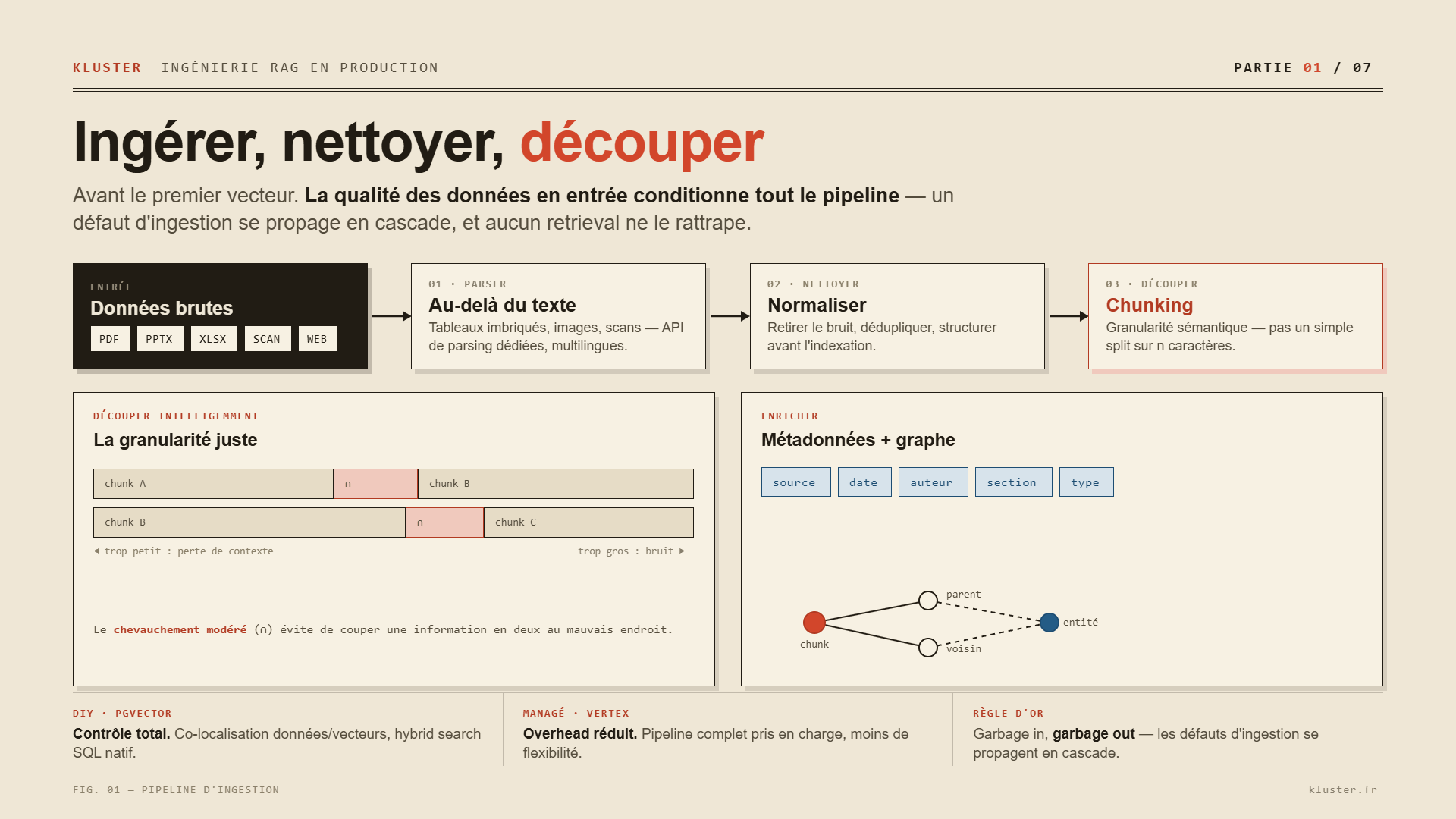
La tentation est grande de sauter directement à l’étape embedding. Erreur. La qualité de vos données en entrée conditionne tout le pipeline. Des documents mal parsés, un découpage arbitraire, l’absence de métadonnées structurées : ces défauts se propagent en cascade et aucune technique de retrieval, aussi sophistiquée soit-elle, ne les rattrapera [1].
Parser au-delà du texte brut
Les données d’entreprise ne se bornent pas à des fichiers .txt. Contrats PDF avec tableaux imbriqués, présentations PowerPoint, feuilles de calcul, images scannées, pages web dynamiques : chaque format exige un parseur adapté. Les systèmes avancés s’appuient sur des API dédiées au parsing de tableaux et d’images, offrant une haute précision dans plusieurs langues [1]. Dans un pipeline multimodal vidéo, l’équipe télécharge les fichiers vidéo générés par IA et utilise des bibliothèques de vision par ordinateur (OpenCV) pour en inspecter les propriétés : génération de vignettes et vérification des fréquences d’images, afin d’établir une vérité-terrain, une fondation de données vérifiées avant leur entrée dans le pipeline [2].
Le choix de l’approche de l’ingestion des documents pour votre Retrieval Augmented Generation est un premier arbitrage structurant :
| Approche | Avantages | Limites |
|---|---|---|
| DIY / base intégrée (ex. PostgreSQL + pgvector, BigQuery vector search) | Contrôle total, co-localisation données vecteur et données opérationnelles, hybrid search native via SQL, faible latence | Gestion d’infrastructure complexe, expertise requise |
| Service managé (ex. Vertex AI Search, Vertex AI RAG Engine) | Pipeline complet (ingestion, chunking, retrieval, assemblage de contexte) pris en charge, overhead opérationnel réduit [3] | Moins de flexibilité, dépendance au fournisseur, personnalisation limitée |
Découper intelligemment
Le chunking est l’art de trouver la granularité juste. Trop gros, le vecteur dilue le signal pertinent dans du bruit. Trop petit, le LLM perd le contexte nécessaire pour comprendre un passage isolé. Il n’existe pas de taille universelle : dans une étude d’évaluation comparative sur 7 318 documents financiers (T2-RAGBench (Akarsu et al., 2026, accepté à EACL 2026)), chaque document moyen contenait environ 920 tokens et était indexé comme unité unique sans découpage, ce qui isolait l’effet de la méthode de retrieval de toute décision de segmentation [4]. Ce choix fonctionne quand la fenêtre de contexte le permet, mais la plupart des corpus d’entreprise nécessitent un découpage thématique ou sémantique, pas un simple split sur n caractères.
Le chevauchement (overlap) entre chunks mérite une attention particulière. Un chevauchement modéré permet de ne pas couper une information en deux au mauvais endroit. Les approches avancées transforment même les chunks pendant la préparation : au lieu de reformuler la requête au moment de la recherche (comme HyDE), elles reformulent les documents eux-mêmes en pré-générant les questions auxquelles chaque chunk répond. L’indexation stocke alors ces questions générées, et la recherche compare question contre question [5].
Enrichir avec des métadonnées et un graphe
Un chunk nu est une information orpheline. Les métadonnées (source, date, auteur, section, type de document) et les relations entre chunks (parent, voisin thématique, lien vers une entité) transforment un simple vecteur en nœud d’un réseau exploitable. L’architecture doit aussi prévoir la mise à jour dynamique des représentations de connaissances, essentielle dans les domaines où les données évoluent, pour garantir l’efficacité du retrieval au fil du temps [6].
2. Choisir et dimensionner le moteur : embeddings, bases vectorielles et indexation

Un besoin en RAG & recherche documentaire ?
Configurez votre projet et recevez un devis clair sous 24h, sans engagement.
L’étape embedding transforme chaque chunk en un vecteur de nombres flottants dans un espace de haute dimension. Ce vecteur est la signature sémantique du texte : deux chunks proches dans cet espace partagent un sens similaire. Le choix du modèle d’embedding et la configuration de la base vectorielle déterminent la qualité de la recherche, le coût d’exploitation et la latence en production.
Modèles d’embedding : éviter le surdimensionnement
Les modèles d’embedding n’ont pas évolué aussi vite que les LLMs ces dernières années [7]. La tentation de choisir le modèle le plus gros est un piège classique : si un modèle léger atteint 85 % de précision en retrieval sur vos données et qu’un modèle deux fois plus gros atteint 87 %, le gain de 2 % ne justifie presque jamais le doublement des coûts et de la latence pour la plupart des applications [7].
L’essentiel est de valider sur vos propres données. Les benchmarks publics comme MTEB mesurent des performances générales sur des tâches variées, mais votre domaine spécifique (contrats juridiques, dossiers médicaux, documentation technique) peut se comporter différemment. La recommandation pragmatique : tester avec 50 à 100 requêtes réelles de votre cas d’usage avant tout déploiement en production [7].
La comparaison entre approches open source et commerciales montre que l’écart s’est considérablement réduit : les modèles open source approchent les performances commerciales sur de nombreuses tâches de retrieval [7]. Ce constat ouvre la porte à des architectures entièrement open source, sans dépendance à un fournisseur pour l’étape embedding.
Dimensionnement et compromis
La dimension du vecteur (384, 768, 1536, 3072…) a un impact direct sur trois variables : la précision du matching, l’espace de stockage et le coût. Des vecteurs plus grands capturent plus de nuances sémantiques, mais consomment proportionnellement plus de RAM et d’espace disque dans la base vectorielle. Ce choix ne s’isole pas : il affecte aussi le coût de la plateforme RAG, qui peut le refléter dans sa tarification [1].
Architecture de la base vectorielle
Le choix de la base vectorielle est un arbitrage entre contrôle et simplicité :
| Critère | PostgreSQL + pgvector | Base spécialisée (Qdrant, Weaviate, Pinecone…) | Service managé |
|---|---|---|---|
| Hybrid search | Native (SQL + vecteur) | Spécialisée, souvent performante | Abstraite |
| Co-localisation données | Excellente (mêmes tables) | Nécessite synchronisation | Gérée par le provider |
| Scalabilité | Limitée par le SGBD | Conçue pour le scale-out | Automatique |
| Opérations | Expertise DBA requise | Expertise vectorielle requise | Minimale |
| Graph traversal | Extensions possibles | Intégration parfois native | Dépend du provider |
La tendance en production est de séparer les responsabilités : stocker les embeddings dans la base vectorielle dédiée tout en maintenant un lookup par chunk_id vers une base graph pour l’enrichissement ou la traversée. Cette architecture permet de conserver un pipeline de retrieval haute performance (incluant hybrid search et reranking) indépendant des traversées de graphe qui peuvent supporter des logiques profondes [1].
3. Dépasser la similarité cosinus : construire un pipeline de retrieval en deux étapes
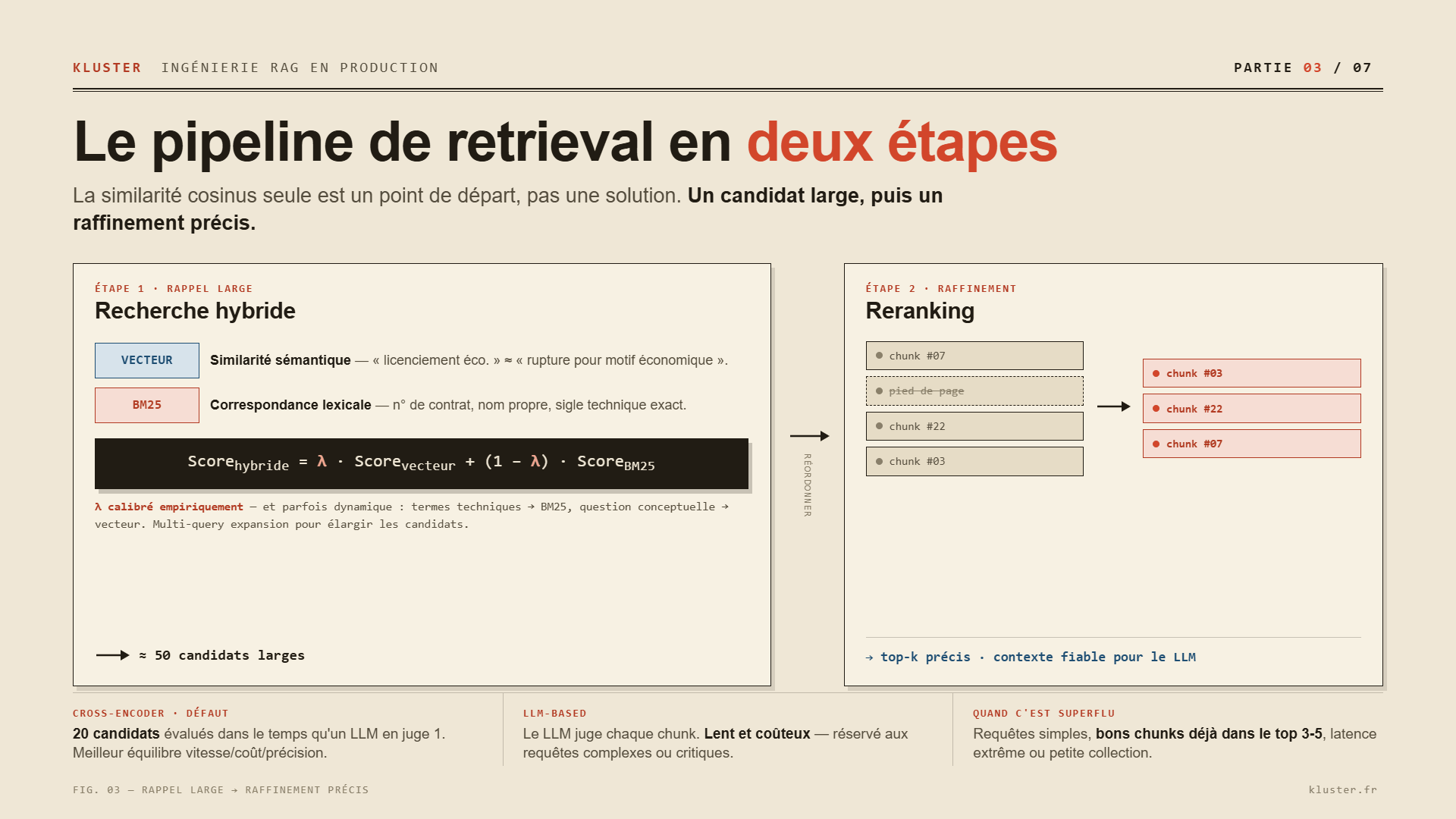
La recherche par similarité vectorielle seule est un point de départ, pas une solution de production. À l’échelle, la qualité se dégrade rapidement si l’on s’en remet uniquement au matching cosinus [1]. Un pipeline de retrieval robuste repose sur deux étapes successives : d’abord un candidat large, puis un raffinement précis.
Première étape : recherche hybride (vecteur + mots-clés)
La recherche hybride combine deux paradigmes complémentaires. La recherche vectorielle capte la similarité sémantique : elle comprend que « licenciement économique » et « rupture du contrat de travail pour motif économique » parlent de la même chose. BM25, la recherche par mots-clés, capte la correspondance lexicale exacte : elle retrouve un numéro de contrat, un nom propre, un sigle technique que le vecteur aurait pu diluer.
La formule classique pondère les deux signaux :
Score_hybrid = λ × Score_vecteur + (1 - λ) × Score_BM25
Le poids λ se calibre empiriquement en mesurant la qualité du retrieval à différents réglages, pour trouver la configuration qui maximise le nombre de chunks corrects récupérés [5]. Certains systèmes vont plus loin en adaptant λ dynamiquement : si la requête contient des termes techniques spécifiques, le poids bascule vers BM25 ; pour une question conceptuelle large, il bascule vers la recherche vectorielle [5].
Une technique complémentaire, la multi-query expansion, génère plusieurs variantes de la requête originale. Chaque variant passe par les deux retrieveurs, élargissant l’ensemble des candidats [5].
Deuxième étape : le reranking
Le reranking évalue chaque candidat retourné par la première étape pour les réordonner par pertinence réelle. C’est cette étape qui transforme un ensemble de chunks « probables » en un contexte fiable pour le LLM.
Deux familles de reranker coexistent :
| Critère | Cross-encoder | LLM-based reranking |
|---|---|---|
| Principe | Modèle entraîné à évaluer la pertinence d’une paire (requête, chunk) | Le LLM juge directement la pertinence de chaque chunk |
| Vitesse | Évalue 20 candidats dans le temps qu’un LLM en évalue 1 [5] | Lent, coûteux en tokenization |
| Coût | Fraction du coût LLM | Élevé par requête |
| Précision | Bonne sur la plupart des cas | Supérieure sur les requêtes complexes |
| Usage recommandé | Défaut pour la majorité des applications [5] | Réservé aux cas critiques ou complexes |
Le cross-encoder est le choix par défaut pour la plupart des applications. Il offre le meilleur équilibre vitesse/coût/précision [5].
Quand le reranking devient-il superflu ?
Le reranking n’est pas toujours nécessaire. Il est superflu quand les requêtes sont simples et que le vecteur store retourne systématiquement les bons chunks dans les trois à cinq premiers résultats, quand les contraintes de latence sont extrêmes, ou quand la collection de documents est suffisamment petite pour que la qualité du retrieval soit déjà élevée sans raffinement supplémentaire [5]. Le tableau des compromis est clair :
| Facteur | Impact |
|---|---|
| Latence requête | Modérée (cross-encoder) à élevée (LLM) : temps d’évaluation par candidat ajouté |
| Coût de préparation | Aucun : le reranking ne modifie ni l’indexation ni le stockage |
| Complexité | Faible à modérée : une étape supplémentaire dans le pipeline |
| Gain de précision | Significatif pour les requêtes complexes ; modeste pour les requêtes simples [5] |
La section suivante montre comment enrichir ce pipeline lorsque la structure même des données dépasse ce que le vecteur et les mots-clés peuvent capturer.
4. Quand le texte ne suffit pas : enrichir le pipeline avec un graphe de connaissances (Kwnowledge Graph)

La recherche vectorielle excelle pour retrouver des passages sémantiquement proches d’une requête. Mais dès qu’une question nécessite de relier des informations dispersées dans plusieurs documents, le vecteur seul atteint ses limites. Un graphe de connaissances (KG) modélise explicitement les entités et leurs relations, ouvrant la porte au raisonnement multi-hop.
Quand passer au GraphRAG ?
Le signal d’alerte est plutôt clair… vos utilisateurs posent des questions dont la réponse nécessite de chaîner des faits. « Quel fournisseur livre le composant X utilisé dans le produit Y dont le rappel a été annoncé en juin ? » requiert trois sauts logiques qu’une simple similarité cosinus ne garantit pas.
Sur le benchmark HotpotQA (113 000 paires question-réponse multi-hop sur Wikipedia), les systèmes GraphRAG améliorent la précision de 15 à 25 % par rapport au RAG traditionnel [6]. Le framework GFM-RAG introduit un mécanisme d’inférence multi-hop en une seule étape qui améliore significativement les performances sur les tâches de raisonnement complexe tout en maintenant l’efficacité, et conforme à la loi de scaling neurale permettant l’expansion du modèle [8].
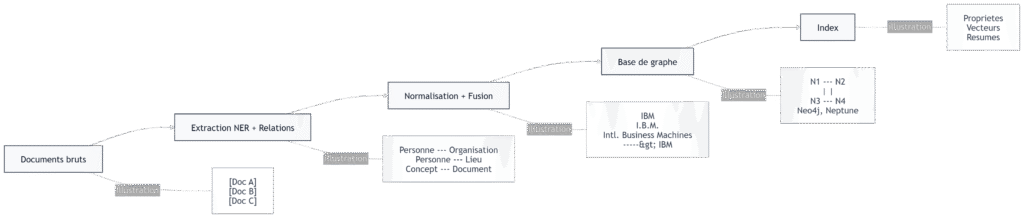
Construire le graphe
La construction du KG suit un pipeline propre :
- Documents bruts
- ▼ Extraction d’entités (NER) + Relations
- ▼ Normalisation & Fusion (dédoublonnage)
- ▼ Base de graphe (Neo4j, Neptune…)
- ▼ Index (propriétés, vecteurs de nœuds, résumés)
Les index et les résumés dans la base de graphe sont conçus pour le filtrage et le classement, jamais pour remplacer les données originales [7]. La documentation Neo4j sur les index et l’optimisation des requêtes fournit un guide officiel pour créer et optimiser les index afin d’améliorer les performances des requêtes [7].
Intégrer le KG au pipeline RAG
L’architecture hybride la plus robuste sépare les deux mondes :
- Recherche vectorielle → chunks pertinents (rapide, sémantique)
- Lookup graphe → enrichissement par les relations entre entités (profondeur logique)
- Fusion → le LLM reçoit à la fois les passages bruts et les faits structurés du graphe
Ce pattern maintient un pipeline de retrieval haute performance indépendant des traversées de graphe qui supportent des logiques de profondeur variable [1].
Évolutions : le graphe temporel et les variantes agentic
Les systèmes avancés ne se contentent pas d’un graphe statique. STAR-RAG, par exemple, mappe les événements sur un graphe de règles aligné temporellement et propage sur ce graphe pour réduire l’espace de recherche et prioriser les preuves temporellement cohérentes, améliorant les performances par rapport au GraphRAG classique [9].
Des ablations montrent l’importance critique de chaque composant dans HippoRAG 2 : sans nœuds de passage, le recall chute de 87,1 à 81,0 ; avec une correspondance NER simplifiée au lieu du linking complet, il chute de 87,1 à 74,6 [10].
La prochaine couche ne concerne plus la recherche, mais la confiance dans ce que le système retourne.
5. Fiabiliser chaque réponse : filtrer, vérifier et attribuer les sources

Un RAG de base récupère des chunks et les passe au LLM. Le problème : la recherche par similarité retourne les chunks les plus proches par le sens, mais « le plus proche » ne signifie pas toujours « pertinent » [5]. Imaginez une requête sur les patterns de conception en IA : le système récupère quatre chunks, trois contiennent des informations utiles sur la réflexion, l’usage d’outils et la planification. Le quatrième est un pied de page bourré de liens de navigation et d’appels à l’action génériques [5]. Sans contrôle qualité, ce bruit pollue la réponse.
Points de contrôle dans le pipeline
L’architecture de fiabilité insère des checkpoints entre chaque étape :
- Requête utilisateur
- ▼ [Checkpoint 1] Filtrage des chunks non pertinents
- ▼ [Checkpoint 2] Vérification de la cohérence (hallucination detection)
- ▼ [Checkpoint 3] Attribution des sources (chaque claim → son chunk)
- ▼ Réponse fiabilisée
Ces techniques d’indexation ont un coût initial élevé mais zéro overhead par requête, tandis que les techniques de vérification sont peu coûteuses à mettre en place mais ajoutent de la latence à chaque requête [5].
Traçabilité et attribution
La traçabilité du LLM exige que chaque affirmation de la réponse soit reliée à un chunk source précis. Quand la réponse du LLM inclut des citations inline, l’utilisation du contexte peut être partiellement observée en notant quels éléments de contexte ont servi à formuler chaque partie de la réponse [1]. Pour une approche plus rigoureuse, la métrique AutoNuggetizer fonctionne ainsi :
- Génération de nuggets : le système extrait des faits atomiques pertinents par rapport à la requête, en analysant la requête et les chunks concernés
- Classification par importance : chaque nugget est classé selon son niveau d’importance
- Évaluation de couverture : la réponse est jugée sur le pourcentage de nuggets importants qu’elle couvre [1]
Évaluer le retrieval lui-même
Avant de juger la réponse, il faut mesurer la qualité du retrieval. Deux métriques fondamentales servent de référence :
- MRR (Mean Reciprocal Rank) : se concentre sur le rang du premier chunk pertinent trouvé. Interprétable et idéal quand trouver une bonne réponse rapidement est l’objectif principal [1].
- MAP (Mean Average Precision) : fournit un résumé plus complet de la qualité du classement en moyennant les scores de précision à chaque position pour chaque requête [1].
| Métrique | Ce qu’elle mesure | Idéal pour |
|---|---|---|
| MRR | Position du premier résultat pertinent | Cas single-answer |
| MAP | Qualité globale du ranking | Cas multi-réponses pertinentes |
| Recall@k | Proportion de chunks pertinents dans les k premiers | Couverture du contexte |
Cohérence, biais et sécurité
L’évaluation ne s’arrête pas à la précision factuelle. La cohérence est essentielle dans les industries réglementées : si un RAG fournit des conseils financiers ou des informations médicales différentes pour une même requête, il devient un outil peu fiable et potentiellement non conforme [1]. L’évaluation doit aussi intégrer des garde-fous de sécurité en filtrant les données récupérées et la réponse générée pour détecter des traits indésirables, du biais ou de la discrimination [1].
Les guardrails en production couvrent un spectre large : conformité aux politiques d’entreprise, absence d’hallucinations, défense contre les attaques par injection de prompt [1]. La section suivante montre comment passer d’un pipeline figé à un système capable de s’adapter.
6. Passer de pipeline statique à système adaptatif : agents, boucles correctives et orchestration (Agentic RAG)

Un RAG classique exécute un pipeline linéaire : requête → retrieval → génération → réponse. Il ne remet jamais en question ses propres résultats. Un RAG agentic introduit des boucles de rétroaction, des capacités de routage dynamique et des mécanismes d’auto-correction.
Les six workflows canoniques agentic
Les systèmes Graph-Based Agentic RAG (GA-RAG) coordonnent le raisonnement à travers six workflows canoniques, chacun orchestre des opérations de graphe, de génération LLM et de synthèse de preuves [6] :
| Workflow | Fonction | Mécanisme |
|---|---|---|
| Prompt chaining | Décomposition séquentielle | Chaque étape alimente la suivante |
| Dynamic routing | Dispatch adaptatif | Sélection vectorielle, graphe ou hybride selon la requête |
| Parallel exploration | Recherche distribuée | Plusieurs chemins explorés simultanément |
| Orchestrator-worker | Décomposition de tâches | L’orchestrateur distribue, les workers exécutent |
| Evaluator-optimizer | Boucles de rétroaction | Évaluation continue et raffinement itératif |
| Self-memory | Contexte persistant | Mémoire épisodique maintenue entre les itérations [6] |
Routage dynamique : vecteur, graphe ou hybride
Le routage adaptatif sélectionne la modalité de retrieval en fonction de la complexité de la requête. Formellement, le résultat du retrieval est une combinaison pondérée :
R(q) = λ × R_vecteur(q) + (1 - λ) × R_graphe(q)
Pour les requêtes factuelles simples, λ tend vers 1 (emphase sur le rappel sémantique). Pour les tâches multi-hop riches en entités, λ tend vers 0 pour privilégier le raisonnement par graphe [6].
Le framework Agent-G illustre cette architecture : il incorpore un pool de retrievers agrégeant les sources textuelles et graphiques, couplé à un agent critique qui valide les réponses et ajuste le routage de manière adaptative [6].
Boucles correctives et adaptation continue
L’axe III de la taxonomie des GA-RAG distingue trois niveaux d’adaptation [6] :
- Statique : pipelines figés sans rétroaction
- Correctif : boucles d’évaluation et de raffinement (ex. agents de validation de graphe)
- Adaptatif : apprentissage continu et mises à jour incrémentales du graphe
Les architectures lifelong GA-RAG maintiennent des connaissances à jour dynamiquement, essentielles dans les domaines où les données évoluent, garantissant des représentations de connaissances et une efficacité de retrieval à jour [6].
Mémoire adaptative
La mémoire d’un agent RAG ne doit pas être un simple historique. Le système FluxMem, par exemple, introduit des structures de mémoire adaptatives avec un gate probabiliste : l’overhead computationnel ajouté pour la sélection de structure et le gating est mineur par rapport au coût de décodage LLM, et n’affecte pas significativement la latence de bout en bout, tout en permettant une utilisation de la mémoire plus adaptative et sélective [11].
Fiabilité de l’orchestration
L’exécution déterministe est un principe clé : une fois le plan établi, l’agent passe en mode exécution en appelant les outils ou agents pertinents qui exécutent leurs portions de travail indépendamment. Chaque composant fonctionne avec un chevauchement minimal, préservant la fiabilité et réduisant le risque d’erreurs migrantes entre tâches [12]. La capacité à intégrer de nouveaux modèles spécialisés à mesure qu’ils sont disponibles, formés ou rendus accessibles, et à retirer les modèles obsolètes, crée un environnement dynamique qui évolue continuellement sans nécessiter de refonte complète de l’architecture [12].
7. Mettre en production : tests, sécurité de la mémoire et mise à l’échelle
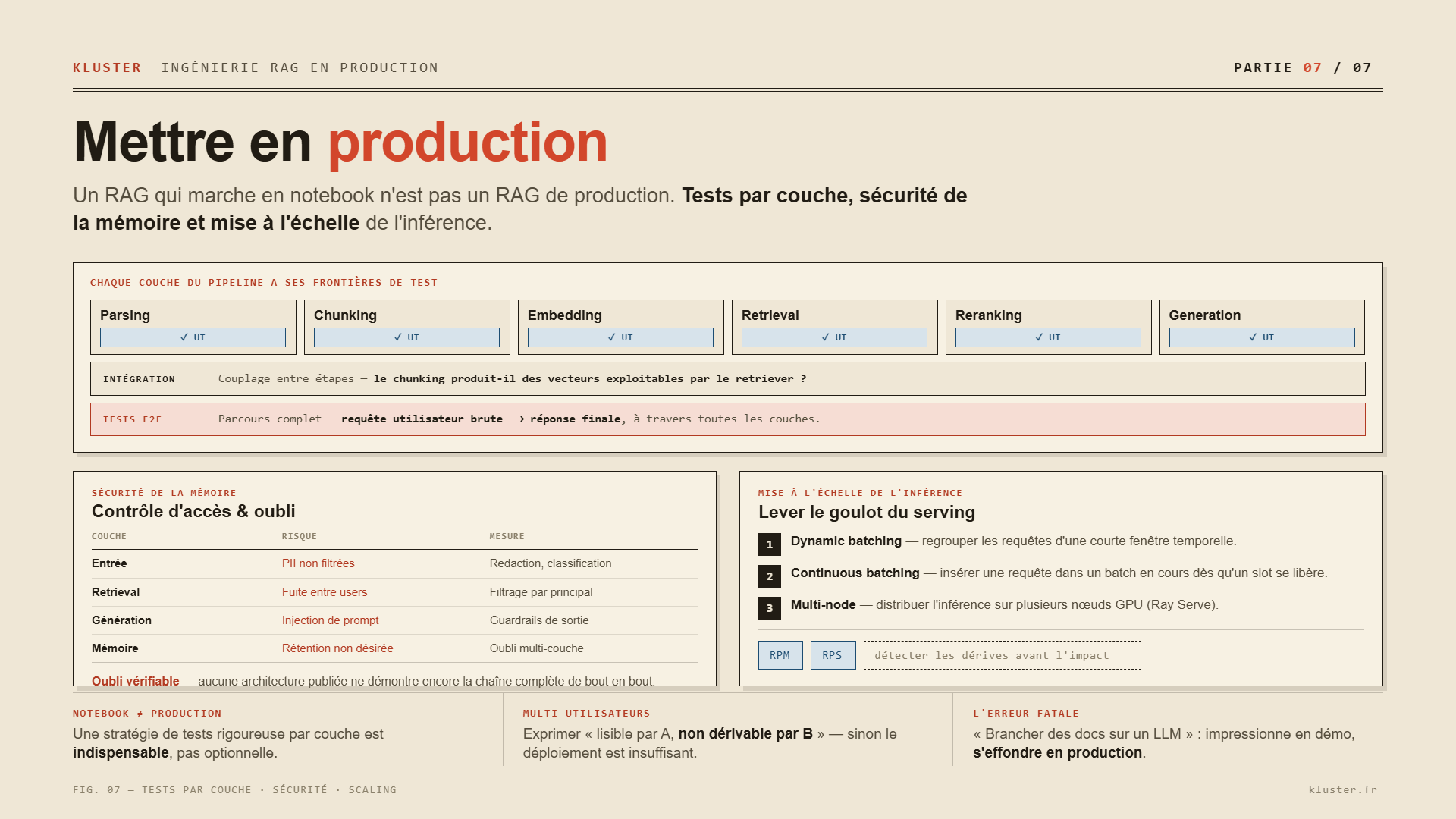
Un RAG qui fonctionne en notebook n’est pas un RAG de production. La mise en production exige une stratégie de tests rigoureuse, une gestion des droits d’accès multi-utilisateurs, un mécanisme d’oubli vérifiable et des techniques d’inférence capables de supporter la charge.
Stratégie de tests spécifique au RAG
Les tests d’un système RAG ne sont pas les tests d’une application web classique. Chaque couche du pipeline possède ses propres frontières de test [13] :
Tests unitaires : ils vérifient qu’une partie isolée du code, généralement une seule fonction ou méthode, fonctionne comme prévu. Pour un RAG typique, on écrit des tests unitaires sur les pipelines de chargement de données, de transformation, de retrieval et de génération. Les frontières de test se situent au début et à la fin de chaque fonction de traitement du pipeline de données [13].
┌─────────────────────────────────────────────────────┐
│ Pipeline RAG │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Parsing │→ │ Chunking │→ │Embedding │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ ↑ UT ↑ UT ↑ UT │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Retrieval│→ │Reranking │→ │Generation│ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ ↑ UT ↑ UT ↑ UT │
│ │
│ ← Tests d'intégration (couplage entre étapes) → │
│ ← Tests E2E (requete brute → réponse finale) → │
└─────────────────────────────────────────────────────┘
Tests d’intégration : ils vérifient que les composants fonctionnent correctement ensemble, par exemple que le chunking produit bien des vecteurs exploitables par le retriever.
Tests E2E : ils simulent un parcours complet, de la requête utilisateur brute à la réponse finale, en passant par toutes les couches.
Pour les agents, des métriques personnalisées permettent d’évaluer la conformité métier. Un exemple concret dans le domaine financier vérifie si les recommandations d’un agent respectent les seuils de risque et de concentration du portefeuille de l’utilisateur [3].
Sécurité de la mémoire et oubli vérifiable
La sécurité dans un RAG multi-utilisateurs dépasse le simple chiffrement. Une politique de retrieval qui ne peut pas exprimer « entrées lisibles par le principal A mais non dérivables par le principal B » est insuffisante pour les déploiements multi-utilisateurs, indépendamment de toute préoccupation adversariale [14].
L’oubli vérifiable est le prochain défi critique. La suppression de données doit être accompagnée d’un protocole vérifiable par audit qui se propage à travers les logs bruts, les résumés, les index et, lorsque c’est techniquement réalisable, les substrats paramétriques. À ce jour, aucune architecture publiée ne démontre cette chaîne complète de bout en bout [14]. C’est un gap à combler pour toute organisation manipulant des données sensibles.
| Couche du pipeline | Risque sécurité | Mesure recommandée |
|---|---|---|
| Données d’entrée | PII, données sensibles non filtrées | PII redaction, classification des données |
| Index / vecteurs | Inférence par reconstruction | Contrôle d’accès par index |
| Retrieval | Fuite de données entre utilisateurs | Politiques de filtrage par principal |
| Génération | Injection de prompt, hallucinations | Guardrails, validation de sortie |
| Mémoire persistante | Rétention non désirée | Oubli vérifiable multi-couche [14] |
Mise à l’échelle de l’inférence
En production, le serving LLM est souvent le goulot d’étranglement. Plusieurs techniques le lèvent :
- Dynamic batching : regrouper les requêtes arrivant dans une fenêtre temporelle courte pour les traiter ensemble
- Continuous batching : insérer de nouvelles requêtes dans un batch en cours d’exécution dès qu’un slot se libère, évitant d’attendre la fin complète du batch [15]
- Multi-node inference : distribuer l’inférence sur plusieurs nœuds GPU avec Ray Serve par exemple [15]
Ces approches ne sont pas mutuellement exclusives. La combinaison continuous batching + multi-node sur Ray Serve est courante pour les systèmes à fort trafic.
La gestion des métriques opérationnelles (requêtes par minute, requêtes par seconde) permet de dimensionner l’infrastructure et de détecter les dérives avant qu’elles n’impactent les utilisateurs [15].
L’erreur à ne pas commettre
Réduire le RAG à « brancher des documents sur un LLM » donne un prototype qui impressionne en démo et s’effondre en production. Chaque couche décrite ici est une brique indispensable : l’ingestion conditionne la qualité des vecteurs, le retrieval conditionne la pertinence du contexte, la vérification conditionne la fiabilité de la réponse, l’orchestration conditionne la capacité d’adaptation, et la mise en production conditionne la survie du système face au trafic réel, aux données sales et aux exigences de conformité [1].
L’ingénierie RAG n’est pas un plugin. C’est une discipline à part entière.
Vous souhaitez construire un RAG adapté à vos données, vos contraintes et vos cas d’usage réels ? Demandez un devis gratuit →
Sources
- [1] Hands-On RAG for Production · Ofer Mendelevitch and Forrest Sheng Bao
- [2] RAG-Driven Generative AI Build MAS-RAG with DualRAG, GraphRAG, multimodal video pipelines, and Oracle Database 23ai
- [3] GenAI on Google Cloud Enterprise Generative AI Systems and Agents
- [4] Benchmarking Ten Retrieval Strategies on Financial QA over Heterogeneous Documents · Meftun Akarsu et al. · 2026 (arXiv:2604.01733)
- [5] RAG Made Simple: The Complete Visual Guide to Retrieval-Augmented Generation · Nir Diamant
- [6] Graph-Based Agentic Retrieval-Augmented_DOI10.13140RG.2.2.26714.30409 · 2025
- [7] RAG with Python Cookbook Practical Recipes from Data Preprocessing to LLM Agents
- [8] LogicPoison Logical Attacks on Graph Retrieval-Augmented Generation · Yilin Xiao et al. · 2026 (arXiv:2604.02954)
- [9] STAR-RAG Temporal Retrieval-Augmented Generation via Graph Summarization · Zulun Zhu et al. · 2025 (arXiv:2510.16715)
- [10] From RAG to Memory Non-Parametric Continual Learning for LLM · Bernal Jiménez Gutiérrez et al. · 2025 (arXiv:2502.14802)
- [11] Choosing How to Remember Adaptive Memory Structures for LLM Agents · Mingfei Lu et al. · 2026 (arXiv:2602.14038)
- [12] Agentic Mesh The GenAI-Powered Autonomous Agent Ecosystem
- [13] Building Generative AI Services with FastAPI A Practical Approach to Developing Context-Rich Generative AI Applications
- [14] ASurvey on the Security of Long-Term Memory in LLM · Zehao Lin et al. · 2026 (arXiv:2604.16548)
- [15] Hands-On LLM Serving and Optimization Hosting LLMs at Scale


