
Quand un avocat copie un contrat confidentiel dans ChatGPT, ces données partent chez un fournisseur tiers. En mars 2023, une faille dans la bibliothèque Redis d’OpenAI a exposé les historiques de conversation de certains utilisateurs, rappelant que ce risque n’est pas théorique [9]. Concevoir un chatbot IA qui fonctionne en production, c’est maîtriser l’architecture, la mémoire conversationnelle, la sécurité et la mesure continue. Voici les choix concrets à faire à chaque étape.
De quoi parle-t-on exactement ?
Les chatbots d’il y a cinq ans reposaient sur des arbres de décision et des scripts de type RPA (Robotic Process Automation, automatisation de tâches répétitives par des robots logiciels) [7 ]. Ils répondaient à des scénarios prévus à l’avance et bloquaient dès que l’utilisateur sortait du cadre.
Le chatbot IA d’aujourd’hui s’appuie sur un grand modèle de langage (LLM, Large Language Model) qui interprète et génère du texte naturel [8]. Il peut comprendre une question formulée librement, maintenir le contexte sur plusieurs échanges, et appeler des outils externes pour rechercher dans une base de données, exécuter du code ou interagir avec un système tiers [2][1]. Les frameworks d’orchestration comme LangChain, CrewAI ou Google ADK permettent déjà de coordonner ces capacités, en acheminant les tâches vers le bon composant selon un ensemble de règles [17].
Mais cette puissance a un coût : complexité d’architecture, risques de sécurité, et nécessité d’évaluer et d’améliorer le système en continu. Les sections suivantes détaillent chaque aspect avec des repères concrets.
Choisir son architecture avant tout
Avant d’écrire un seul prompt, il faut décider de l’architecture. Trois niveaux de complexité s’offrent à vous.
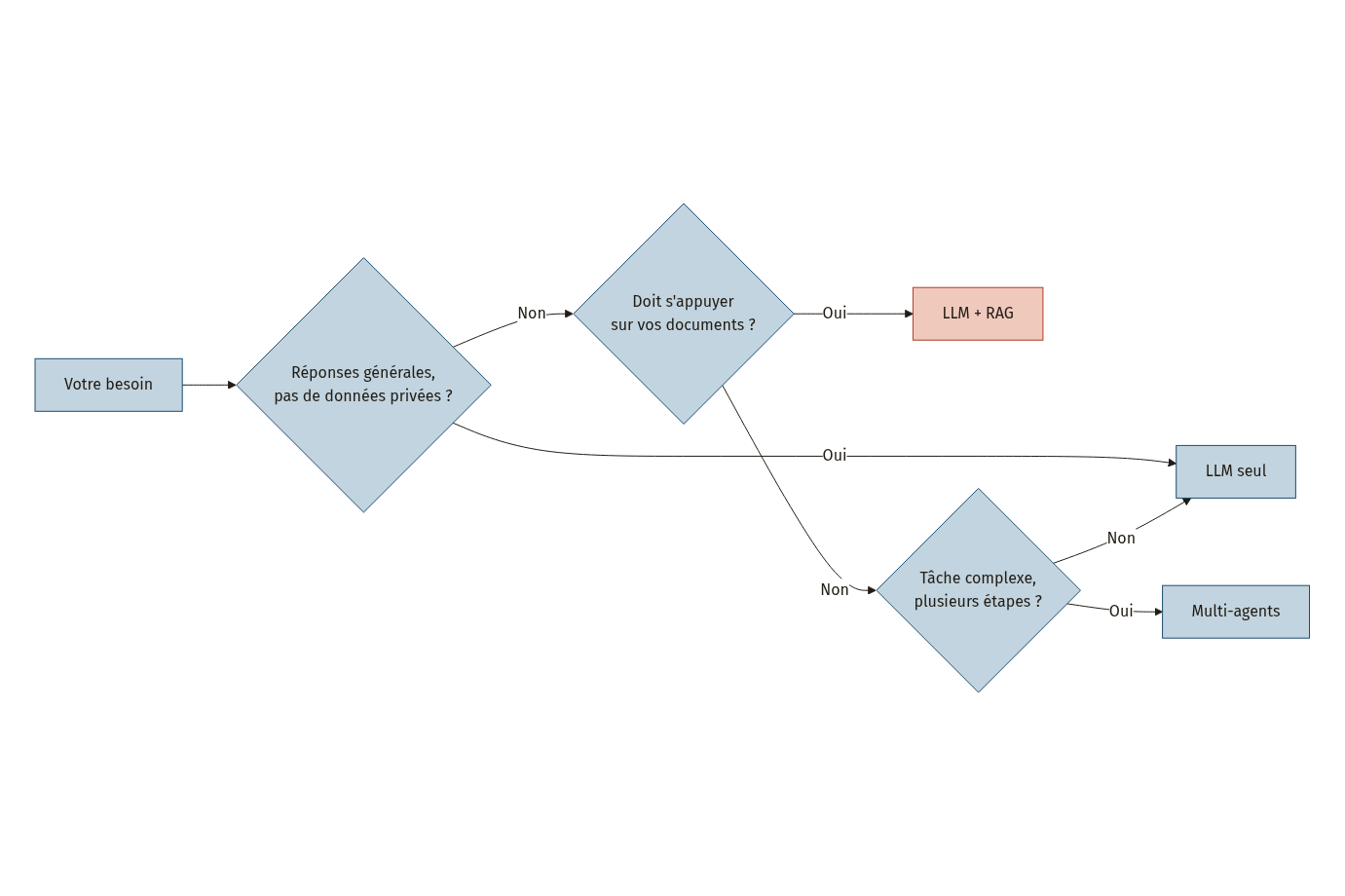
Niveau 1 : le LLM seul. Un modèle de langage utilisé directement, sans source de données externe. Convient pour des assistants généraux, du brainstorming ou de la rédaction créative. Configuration la plus simple et la moins coûteuse.
Niveau 2 : LLM + RAG. Le RAG (Retrieval-Augmented Generation) consiste à enrichir les réponses du modèle en y injectant des documents pertinents tirés de votre base de données, au moment de la requête [4]. Concrètement, le système cherche d’abord les passages les plus proches de la question de l’utilisateur dans vos documents (contrats, FAQ, documentation produit), puis les envoie au modèle comme contexte supplémentaire. C’est la bonne option quand vos réponses doivent être ancrées dans des données fiables et actualisées. Le système RAG-PRISM utilise cette approche pour un tuteur adaptatif qui récupère des ressources pédagogiques pertinentes avant de répondre [3].
Niveau 3 : multi-agents. Quand la tâche requiert plusieurs compétences (rechercher, analyser, synthétiser), un seul LLM montre vite ses limites [4]. Le framework OmniNova a démontré qu’une organisation hiérarchique d’agents spécialisés améliore significativement le taux de complétion des tâches par rapport à un réseau plat, grâce à la réduction de la surcharge computationnelle [4]. Le framework Autonoma propose une architecture modulaire de ce type, avec décomposition des tâches et orchestration hiérarchique [21].
| Critère | LLM seul | LLM + RAG | Multi-agents |
|---|---|---|---|
| Complexité de mise en place | Faible | Moyenne | Élevée |
| Fiabilité des réponses | Dépend des connaissances du modèle | Ancrée dans vos données | Variable, selon la coordination |
| Coût par requête | Faible (1 appel LLM) | Moyen (retrieval + 1 appel LLM) | Élevé (multiples appels par tâche) |
| Cas d’usage typique | Assistant général | FAQ produit, support juridique | Recherche + analyse + synthèse |
À retenir : commencez par le niveau le plus simple qui couvre votre besoin. Montez en complexité seulement quand les limites du niveau actuel deviennent un obstacle mesurable pour vos utilisateurs.
Garder le fil : la mémoire sur plusieurs tours
La majorité des chatbots échouent au-delà du premier échange. L’utilisateur reprend la conversation trois messages plus tard et le bot a tout oublié. Ce n’est pas un défaut cosmétique, c’est la première cause d’abandon.
Agents IA : l'approche
Comment je le conçois concrètement : étapes, livrables et garde-fous.
Pourquoi le modèle « oublie »
Un LLM a une fenêtre de contexte limitée (le nombre de tokens, c’est-à-dire de morceaux de texte, qu’il peut traiter simultanément). Au-delà, les messages les plus anciens sont ignorés. Les modèles actuels gèrent de 128 000 tokens (GPT-4o) à 1 million de tokens (Gemini 1.5 Pro), mais même à l’intérieur de cette fenêtre, le modèle a tendance à privilégier les informations récentes [34][29]. Des approches comme Longformer ou Transformer-XL étendent la portée de l’attention, tandis que des outils comme SnapKV ou LLMLingua compressent les séquences de tokens pour optimiser l’espace disponible [5].
Les quatre stratégies de gestion
Un survey de 2025 sur la modélisation de contextes longs identifie quatre familles de solutions [33], que les systèmes LLMOps en production combinent couramment, en distinguant mémoire court terme (conversation en cours) et long terme (au-delà d’une session) [31] :
| Stratégie | Principe | Quand l’utiliser |
|---|---|---|
| Fenêtre de contexte élargie | Augmenter le nombre de tokens visibles par le modèle | Conversations courtes, budget conséquent |
| Mémoire à base de retrieval | Stocker les échanges dans une base vectorielle, récupérer les plus pertinents | Conversations longues, informations éparses |
| Compression de contexte | Résumer ou compresser les échanges anciens pour libérer de l’espace | Historiques volumineux, contraintes de coût |
| Mémoire agentique | L’agent décide lui-même quoi mémoriser et quoi oublier | Systèmes autonomes, multi-tours prolongés |
Le benchmark EvoMemBench a évalué ces approches sur cinq scénarios réalistes (système de fichiers Gorilla, contrôle de véhicules, bots de trading, réservation de voyages) [32]. Résultat : aucune méthode n’est universellement supérieure. Les approches à base de retrieval (BM25, embeddings sémantiques Qwen3-Emb-4B, GraphRAG) performent bien sur la plupart des scénarios, mais le contexte long natif (Gemini 3-Flash) reste compétitif sur certaines tâches [6]. Ce qui signifie concrètement qu’il faut tester plusieurs approches sur vos propres données.
Personnaliser au fil de la conversation
Au-delà de la rétention d’information brute, la personnalisation améliore l’engagement. Un modèle entraîné avec une « récompense de curiosité » (qui valorise les questions orientées vers les préférences de l’utilisateur) génère des dialogues plus personnalisés et plus engageants sur plusieurs tours [6].
À retenir : ne comptez pas sur la seule fenêtre de contexte du modèle. Combinez au moins deux approches (par exemple retrieval pour les faits, compression pour l’historique) et testez sur des conversations réelles de 5 à 10 échanges avant de déployer sur des scenarii plus longs, car la détection d’hallucinations devient significativement plus difficile au-delà d’un certain volume de contexte [30].
Sécuriser les conversations : données, garde-fous, coûts
Un chatbot qui fuit des données personnelles ou génère des réponses toxiques peut détruire la confiance en quelques heures.
Le risque concret de fuite
Le cas le mieux documenté : en mars 2023, la vulnérabilité Redis d’OpenAI a exposé les historiques de certains utilisateurs de ChatGPT, y compris les quatre derniers caractères de numéros de carte bancaire [9]. Le cadre LegalGuardian, développé pour le secteur juridique, recommande d’anonymiser systématiquement les données personnelles (noms, adresses, numéros de dossier) avant de les soumettre à un LLM [7]. Un avocat qui copie un contrat confidentiel dans un chatbot public envoie ces données à un fournisseur tiers, potentiellement en violation du secret professionnel.
Les attaques sur la mémoire
Dans un système avec mémoire persistante, des entrées malveillantes peuvent être stockées puis « rappelées » plus tard pour biaiser les décisions du système. Le phénomène de « goal hijacking » (détournement d’objectif) survient quand un attaquant injecte des instructions dissimulées dans des données que l’agent internalise au fil des échanges. On observe aussi des attaques par consommation : l’attaquant force le système à effectuer des appels coûteux en boucle [20].
Un autre vecteur est la « role confusion » (confusion de rôle) : en cassant les séparateurs entre instruction système, message utilisateur et réponse assistant, un attaquant peut faire internaliser des directives malveillantes sur plusieurs tours de conversation [8].
Checklist de sécurité
| Risque | Mesure concrète | Priorité |
|---|---|---|
| Fuite de données personnelles (PII) | Anonymiser les données avant envoi au LLM [7] | Haute |
| Enpoisonnement de la mémoire | Valider et sanitizer chaque entrée avant stockage vectoriel [8] | Haute |
| Coûts incontrôlés (attaques par consommation) | Quotas de tokens par utilisateur et par session [8] | Moyenne |
| Contournement des garde-fous | Tests comportementaux réguliers avec des prompts adverses [8] | Moyenne |
| Dépendance plateforme (verrouillage fournisseur) | Prévoir une abstraction de l’appel LLM, un fallback possible [10] | Moyenne |
À retenir : sécurisez les données dès la conception (anonymisation, quotas), pas après le premier incident. Testez vos garde-fous avec des scénarios adverses avant le déploiement.
Mesurer dès le premier jour
Déployer un chatbot sans instrumentation, c’est piloter à l’aveugle.
Un besoin en agents IA ?
Configurez votre projet et recevez un devis clair sous 24h, sans engagement.
« Lead » et « lag » : ne pas confondre ce qu’on pilote avec ce qu’on observe
L’étude sur l’évaluation et l’amélioration continue d’un assistant IA entreprise introduit une distinction cruciale [13] :
- Métriques lag (retardées) : rétention utilisateur, satisfaction globale, engagement dans le temps. Visibles uniquement après déploiement, elles ne permettent pas d’ajuster le système en temps réel.
- Métriques lead (pilotes) : précision des réponses, nombre de tokens par échange, complexité perçue par l’utilisateur, taux de complétion des tâches. Ce sont elles qui guident l’amélioration continue, avant et après le lancement [9].
| Métrique | Type | Actionnable avant déploiement ? |
|---|---|---|
| Précision des réponses | Lead | Oui (tests hors ligne) |
| Tokens par conversation | Lead | Oui (monitoring) |
| Complexité perçue par l’utilisateur | Lead | Oui (tests utilisateurs) |
| Taux de complétion des tâches | Lead | Oui (scénarios de test) |
| Satisfaction globale | Lag | Non (après déploiement) |
| Rétention utilisateur | Lag | Non (après déploiement) |
Surveillez la complexité perçue : l’étude Chatbots for Robotic Process Automation montre que les tâches perçues comme simples (note moyenne de 1,4 sur 4) sont confiées spontanément au bot, tandis que les tâches perçues comme difficiles (note 3,8 sur 4) génèrent de la réticence [12]. Si vos utilisateurs évitent le chatbot sur certaines tâches, le problème est peut-être la barrière perçue, pas le chatbot lui-même.
Les trois métriques clés pour un système RAG
Si votre chatbot utilise le RAG, trois métriques couvrent les modes de défaillance indépendants [27] :
- Fidélité (faithfulness) : la réponse dit-elle des choses réellement supportées par les documents récupérés ? Une réponse peut être bien formulée mais inventée.
- Pertinence de la réponse (answer relevancy) : la réponse traite-t-elle réellement la question posée ? Un système peut être fidèle au contexte mais hors sujet.
- Précision du contexte (context precision) : les documents récupérés étaient-ils réellement pertinents pour la question ? Un retrieval médiocre compromet tout le pipeline en aval.
Une seule de ces métriques peut être excellente tandis que les deux autres échouent : c’est pourquoi les mesurer ensemble est indispensable [10].
L’approche la plus accessible pour les mesurer est le LLM-as-Judge (un modèle de langage qui évalue les réponses d’un autre). Le framework RAGEval génère automatiquement des jeux de données d’évaluation adaptés à vos propres scénarios [24]. Pour les domaines techniques de niche, le benchmark FreshStack propose des métriques de diversité et de couverture (α-nDCG, Coverage, Recall), en mesurant non pas la pertinence document par document, mais la richesse informationnelle globale de ce que le système récupère [26].
Observer le retrieval
Dans un pipeline RAG, les défaillances viennent le plus souvent de l’étape de retrieval (récupération des documents), pas du modèle de langage lui-même [22]. Le système MiRAGE utilise des rerankers multimodaux pour affiner les résultats de retrieval sémantique avant de les passer au modèle, démontrant l’importance de cette étape intermédiaire [25].
Loggez systématiquement l’ensemble des documents récupérés pour chaque requête, avec leur score de similarité. Dans les systèmes LLMOps matures, cette traçabilité permet une analyse rétrospective et la reproductibilité des résultats [23].
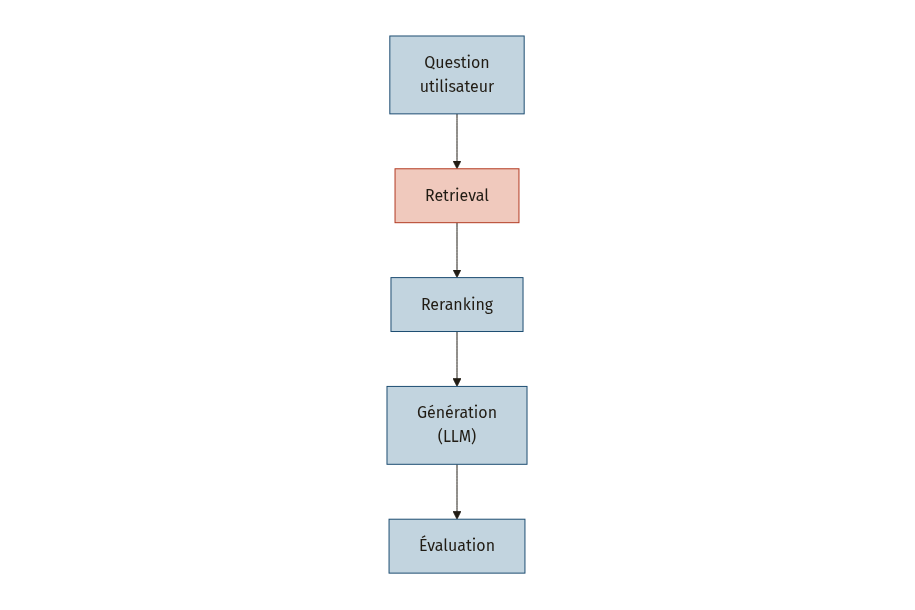
À retenir : instrumentez les métriques lead dès le premier jour. Elles vous permettent d’ajuster le système avant que les métriques lag ne remontent, parfois plusieurs semaines après le déploiement.
Améliorer en boucle : le chatbot n’est jamais « fini »
Un chatbot en production est un système vivant. Les attentes des utilisateurs évoluent, vos données changent, les modèles sous-jacents sont mis à jour. Construire une boucle d’amélioration continue est aussi important que le déploiement initial.
La boucle d’évaluation
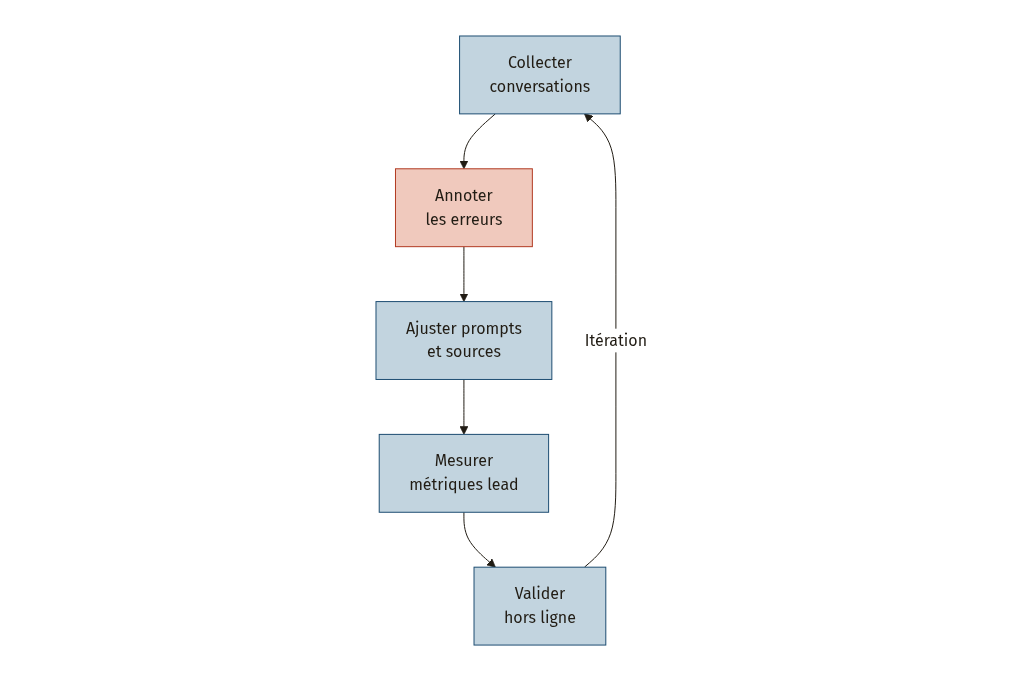
Collecter un échantillon représentatif. Ne vous contentez pas de vos conversations « faciles ». Le système MARAUS, un assistant d’admission universitaire basé sur des agents multi-RAG, a inspecté 6 079 paires questions-réponses pour évaluer rigoureusement ses performances [11]. Visez un échantillon qui couvre la diversité réelle des requêtes de vos utilisateurs.
Annoter les erreurs. Identifiez les modes de défaillance : réponse incorrecte, hallucination, réponse hors sujet, retrieval insuffisant. L’annotation humaine reste la référence, mais le LLM-as-Judge offre un bon premier filtre à moindre coût [14][11].
Ajuster. Sur la base des erreurs identifiées, modifiez vos prompts, enrichissez vos sources de données ou réajustez les paramètres de retrieval. Surveillez la fraîcheur des documents récupérés et leur pertinence contextuelle [12].
Valider hors ligne. Avant de pousser une mise à jour en production, testez sur un jeu de données de validation. Le framework RAGEval permet de générer automatiquement des benchmarks adaptés à votre domaine [11].
Le coût réel : surveiller les tokens
Le token est l’unité de consommation d’un LLM. Chaque entrée (question + contexte récupéré) et chaque sortie (réponse) sont comptabilisées. Dans le cadre du système MARAUS, la consommation quotidienne varie entre 350 000 et 1,4 million de tokens, avec une moyenne de 1 748 tokens d’entrée et 60 tokens de sortie par message [13]. Ce ratio (environ 29 fois plus de contexte envoyé que de réponse générée) illustre l’importance du contexte dans un pipeline RAG. Ces chiffres sont spécifiques à un système d’admission universitaire : les vôtres dépendront de la complexité de vos requêtes et du volume de documents récupérés.
Pour contrôler les coûts :
– mettez des quotas par utilisateur et par session,
– compressez le contexte quand c’est possible (des techniques comme LLMLingua réduisent le nombre de tokens envoyés au modèle sans perte significative d’information [5]),
– surveillez le ratio tokens entrée/sortie : un ratio trop élevé signifie probablement que vous envoyez du contexte inutile au modèle.
Le canal de déploiement influence tout
Où vos utilisateurs interagissent-ils avec le chatbot ? Le choix du canal (messagerie existante, interface web dédiée, intégration dans un outil métier) a un impact direct sur l’adoption. L’étude sur les chatbots de développement logiciel a déployé son prototype sur Facebook Messenger, mais souligne que ce choix de plateforme peut ne pas représenter tous les environnements de travail des développeurs [14]. Si vos utilisateurs vivent déjà dans Teams, Slack ou un CRM, intégrez le chatbot là où ils sont plutôt que de leur demander d’ouvrir un nouvel onglet.
Plus la tâche parait complexe à l’utilisateur, moins il envisagera de confier cette tâche au chatbot [15]. Pour réduire cette barrière, guidez les premières interactions avec des exemples de questions et montrez des résultats concrets dès le premier échange.
À retenir : formalisez la boucle collecte, annotation, ajustement, validation. Surveillez vos coûts en tokens dès le premier jour. Choisissez un canal de déploiement que vos utilisateurs fréquentent déjà, et réduisez explicitement la complexité perçue des premières interactions pour maximiser l’adoption.
Sources
- [1] Building Applications with AI Agents Designing and Implementing Multiagent Systems · livre · Amazon
- [2] Context Engineering From Prompts to Corporate Multi-Agent Architecture · V.V.Vishnyakova, Ph.D. · 2026 · preprint · arXiv:2603.09619
- [3] RAG-PRISM: A Personalized, Rapid, and Immersive Skill Mastery Framework with Adaptive Retrieval-Augmented Tutoring · preprint · arXiv:2509.00646
- [4] OmniNova:A General Multimodal Agent Framework · preprint · arXiv:2503.20028
- [5] From Business Events to Auditable Decisions: Ontology-Governed Graph Simulation for Enterprise AI · preprint · arXiv:2604.08603
- [6] EvoMemBench: Benchmarking Agent Memory from a Self-Evolving Perspective · preprint · arXiv:2605.18421
- [7] LegalGuardian: A Privacy-Preserving Framework for Secure Integration of Large Language Models in Legal Practice · preprint · arXiv:2501.10915
- [8] SoK: The Attack Surface of Agentic AI — Tools, and Autonomy · Ali Dehghantanha et al. · 2026 · preprint · arXiv:2603.22928
- [9] Evaluation and Continual Improvement for an Enterprise AI Assistant · preprint · arXiv:2407.12003
- [10] RAG with Python Cookbook Practical Recipes from Data Preprocessing to LLM Agents · livre · Amazon
- [11] RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework · Kunlun Zhu et al. · 2024 · preprint · arXiv:2408.01262
- [12] LLMOps Managing Large Language Models in Production · livre · Amazon
- [13] An Empirical Study of Multi-Agent RAG for Real-World University Admissions Counseling · Anh Nguyen-Duc et al. · 2025 · preprint · arXiv:2507.11272
- [14] Enhancing Software Development with Context-Aware Conversational Agents: A User Study on Developer Interactions with Chatbots · preprint · arXiv:2505.08648
- [15] Chatbots for Robotic Process Automation: Investigating Perceived Trust and User Satisfaction · preprint · arXiv:2302.00397


