Chaque fois que vous tapez une consigne dans ChatGPT, Claude, Gemini ou DeepSeek, vous fournissez au modèle la totalité de son espace de travail : une question, parfois un contexte, et la forme de réponse attendue [1]. L’écart entre une réponse générique et une réponse véritablement exploitable tient à ce que vous avez formulé dans ce champ de saisie. Apprendre à rédiger un bon prompt, c’est apprendre à parler à un interlocuteur brillant mais parfaitement littéral, qui dépend entièrement de vos mots [2].
1. Ce que le modèle « voit » quand vous écrivez
Un modèle de langage ne devine pas vos intentions. Il traite exactement ce que vous lui donnez : une question, un contexte, et c’est tout [1]. Ce fonctionnement impose une représentation mentale simple, celle d’un « apprenti brillant » (bright apprentice), un collaborateur très compétent, prêt à agir, mais qui a besoin d’instructions limpides et sans ambiguïté pour produire un résultat pertinent [2].
Concrètement, quand vous écrivez « Fais-moi un résumé », le modèle ne sait pas de quoi, pour qui, à quelle longueur, ni sous quelle forme. Il devine, et le résultat reflète cette incertitude. Si en revanche vous écrivez « Résume ce texte en 5 bullet points pour un public non technique », vous supprimez les zones d’ombre et le modèle sait exactement ce qu’on attend de lui.
C’est la première leçon : chaque mot de votre prompt compte, car le modèle ne dispose que de vos mots.
2. La formule de base : rôle, instruction, contexte, format
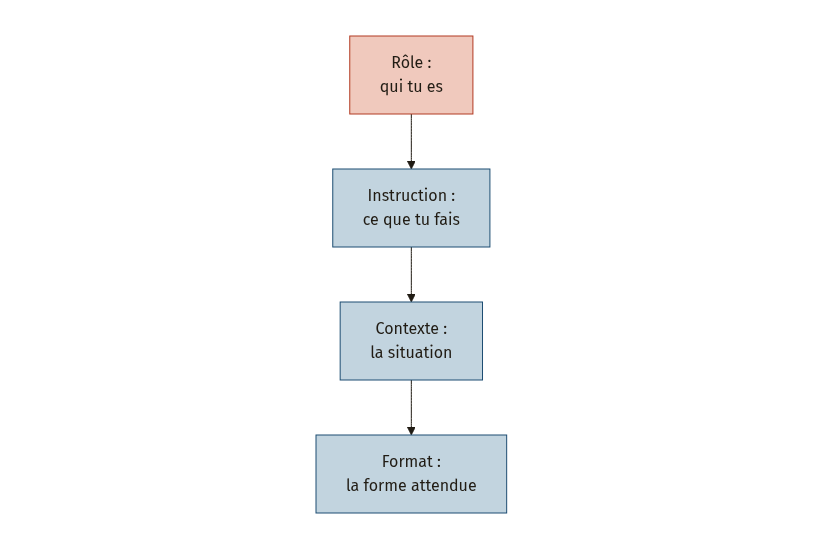
Un prompt se construit autour de quatre blocs. L’ordre n’est pas figé, mais chaque bloc remplit une fonction précise :
- Rôle : définissez l’identité que le modèle doit adopter (« Tu es un expert-comptable spécialisé dans les PME ») [3].
- Instruction : dites clairement ce que vous attendez (« Rédige un email de relance pour une facture impayée »).
- Contexte : fournissez la situation, les données, les contraintes (« Le client n’a pas payé la facture n°4821, envoyée il y a 30 jours »).
- Format : précisez la forme de la sortie (« En 3 paragraphes, ton professionnel mais courtois ») [4].
En pratique, voici la différence entre un prompt vague et un prompt structuré :
| Élément | Prompt vague | Prompt structuré |
|---|---|---|
| Rôle | (absent) | « Tu es un rédacteur spécialisé B2B » |
| Instruction | « Écris un post LinkedIn » | « Rédige un post LinkedIn de 150 mots sur l’impact de l’IA dans la comptabilité » |
| Contexte | (absent) | « Cible : dirigeants de PME francophones. Angle : gain de temps, pas de technique » |
| Format | (absent) | « Commence par une question percutante. Termine par un appel à l’action. Pas d’emojis. » |
La différence de qualité entre les deux résultats est immédiate [4].
3. Les cinq leviers qui changent la qualité des réponses
Au-delà de la structure de base, cinq principes fondamentaux déterminent si votre prompt produira une réponse médiocre ou excellente [4].
Contenu & rédaction IA : l'approche
Comment je le conçois concrètement : étapes, livrables et garde-fous.
Précision : chaque mot vague coûte cher
« Écris quelque chose sur le marketing » est l’exemple type de prompt inefficace. Le modèle ne sait pas quel aspect du marketing, pour quel public, à quelle longueur, pour quelle plateforme. Comparez avec : « Rédige une introduction de 200 mots pour un article de blog sur les bénéfices des outils d’automatisation marketing pour les petites entreprises » [4].
La règle d’or : si vous pouvez imaginer deux interprétations très différentes de votre prompt, le modèle le pourra aussi.
Contexte : plus le modèle sait, moins il invente
Donnez au modèle tout ce dont il a besoin pour agir. Un prompt comme « Rédige une description de produit » ne contient aucune information exploitable. En revanche : « Rédige une description de 50 mots pour un casque sans fil à réduction de bruit, destiné aux jeunes professionnels travaillant dans des bureaux ouverts. Mettez en avant les bénéfices de la réduction de bruit pour la concentration et la productivité » [4] donne au modèle une cible claire.
Le contexte agit comme un filtre : il réduit l’espace des réponses possibles et concentre le modèle sur ce qui vous intéresse.
Exemples : montrer plutôt que décrire
Pour des tâches complexes ou inhabituelles, fournir un ou plusieurs exemples de la sortie attendue est souvent plus efficace que de la décrire en mots. C’est le principe du few-shot prompting (prompt avec exemples) : vous montrez au modèle un ou plusieurs couples « entrée, sortie » représentatifs, et il reproduit le schéma [5][6].
Un seul exemple suffit pour des tâches simples comme la traduction. Pour des tâches plus complexes, comme classifier des tickets de support ou identifier le ton d’un texte, plusieurs exemples donnent de meilleurs résultats [5].
Contraintes : dire ce que le modèle ne doit PAS faire
Un prompt qui ne spécifie que le positif laisse trop de liberté. Ajoutez des gardes-fous explicites : « Ne mentionne pas de concurrents par nom », « Ne donne pas de conseils médicaux », « Ne dépasse pas 200 mots ». Les contraintes cadrent la réponse tout autant que les instructions.
Itération : accepter que le premier essai ne soit pas le bon
Rédiger un prompt efficace est un processus itératif : on expérimente, on analyse le résultat, on affine, on réessaie [1][4]. Ce n’est pas un échec de devoir reformuler, c’est la méthode elle-même. Un prompt fonctionnel arrive rarement du premier coup, surtout pour des tâches complexes.
4. Les paramètres invisibles qui modèlent la réponse
En plus de votre texte, trois paramètres techniques influencent directement ce que le modèle produit. Vous pouvez les régler selon l’API ou l’interface que vous utilisez [4].
Température : le curseur créativité contre précision
La température contrôle le degré d’aléatoire dans la génération de chaque mot [3][7].
- Température basse (proche de 0) : le modèle choisit presque toujours le mot le plus probable. Le résultat est prévisible, cohérent, parfois répétitif. Idéal pour du code, des réponses factuelles, de l’extraction de données [7].
- Température haute (0.7, 0.8 ou plus) : le modèle prend plus de risques. Le résultat est plus varié, plus créatif, parfois incohérent. Utile pour du brainstorming, de la rédaction créative, de la génération d’idées [7][5].
Top-P (échantillonnage par noyau) : restreindre le vivier de mots candidats
Top-P (aussi appelé nucleus sampling) définit un seuil de probabilité cumulée. En termes concrets, si vous réglez Top-P à 0.9, le modèle ne considère que l’ensemble de mots les plus probables dont la probabilité cumulée atteint 90 %, ignorant les choix les plus improbables [3][5]. Plus la valeur est basse, plus la réponse est cadrée.
Max tokens : borner la longueur
Max tokens fixe le nombre maximum de morceaux de texte (tokens, c’est-à-dire environ des mots ou des sous-mots) que le modèle peut générer. Limiter cette valeur permet de contrôler la longueur de la réponse et, accessoirement, le coût de l’appel API [4].
Voici des réglages de départ raisonnables selon le cas d’usage :
| Cas d’usage | Température | Top-P | Max tokens |
|---|---|---|---|
| Extraction factuelle, classification | 0.0 à 0.3 | 0.1 à 0.5 | Adapté à la tâche |
| Résumé, reformulation | 0.3 à 0.5 | 0.7 à 0.9 | 200 à 500 |
| Rédaction créative, brainstorming | 0.7 à 0.9 | 0.9 à 1.0 | 500 à 2 000 |
| Évaluation, jugement structuré | 0.0 | 1.0 | 500 à 1 000 |
Ces valeurs ne sont pas des normes universelles, mais des points de départ à affiner selon vos résultats [8][9][10].
5. Techniques avancées : quand les bases ne suffisent plus
Pour des tâches complexes (raisonnement multi-étapes, extraction de données rares, jugement qualitatif), les techniques de base atteignent leurs limites. Plusieurs méthodes avancées permettent de franchir ce palier [2].
Chain-of-thought : obliger le modèle à montrer son raisonnement
Ajouter l’instruction « raisonne étape par étape » dans votre prompt force le modèle à exposer son cheminement avant de donner sa réponse finale [6][11]. Cette technique, appelée chain-of-thought prompting (chaîne de raisonnement), améliore significativement la justesse sur les tâches logiques, mathématiques et de compréhension complexe [12][13].
En pratique, il suffit d’ajouter : « Montre ton raisonnement étape par étape avant de donner ta réponse finale. »
Few-shot stratégique : choisir ses exemples avec soin
La technique du few-shot prompting prend toute sa puissance quand les exemples sont sélectionnés stratégiquement. En fournissant au modèle plusieurs couples « entrée, sortie » représentatifs, vous lui montrez le schéma exact à reproduire, sans avoir à le décrire formellement [5][6]. C’est particulièrement efficace pour les tâches de classification, de formatage ou de stylométrie.
Self-consistency : voter entre plusieurs raisonnements
La self-consistency (cohérence interne) consiste à exécuter le même prompt plusieurs fois, puis à sélectionner la réponse qui revient le plus souvent [2][12]. Le principe : si le même raisonnement apparaît dans plusieurs essais indépendants, il est plus fiable. Cette technique réduit les erreurs sur les tâches d’arithmétique, de bon sens et de raisonnement symbolique [2].
Prompt paraphrasing : reformuler pour mieux couvrir
Plutôt que d’envoyer une seule version de votre prompt, vous pouvez le reformuler de plusieurs façons et agréger les résultats [2]. Chaque formulation légèrement différente éclaire le sujet sous un angle différent, ce qui améliore la couverture globale. Utile en extraction d’information et en recherche documentaire.
Démonstration ensembliste (DENSE) et Mixture of Reasoning Experts (MoRE)
Pour les tâches à fort enjeu, deux techniques vont plus loin :
- DENSE : vous créez plusieurs jeux de few-shot examples différents et combinez les réponses produites par chacun [2].
- MoRE : vous demandez au modèle de jouer plusieurs rôles d’expert différents, chacun évalue la question selon son angle, puis vous agrégez les jugements [2].
Ces méthodes sont plus coûteuses en appels API, mais produisent des résultats plus robustes sur les tâches difficiles.
La bonne nouvelle : des modèles légers, correctement accompagnés par des prompts soigneusement conçus, peuvent égaler ou dépasser les performances de modèles plus gros [14]. L’effort investi dans le prompt est souvent plus rentable que le passage à un modèle plus grand.
6. Quand ça ne marche pas : diagnostiquer et corriger
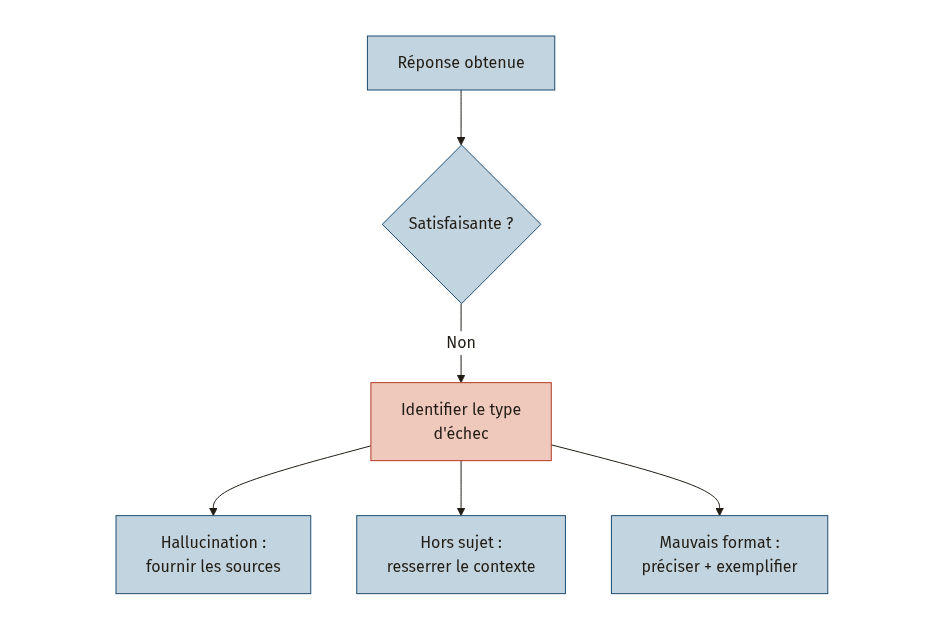
Un prompt qui donne un résultat insatisfaisant n’est pas nécessairement raté : il est peut-être simplement inachevé. Trois modes d’échec reviennent le plus souvent, chacun avec sa solution [15].
Un besoin en contenu & rédaction IA ?
Configurez votre projet et recevez un devis clair sous 24h, sans engagement.
Hallucination : le modèle invente des faits
L’hallucination c’est quand le modèle produit des informations fausses ou non présentes dans les données fournies [15].
Solution : fournissez explicitement les données ou documents dont le modèle doit extraire sa réponse. Ajoutez la contrainte : « Réponds uniquement en te basant sur le texte fourni ci-dessous. Si l’information n’y figure pas, indique que tu ne sais pas. » [15].
Réponse hors-sujet : le modèle répond, mais pas à la bonne question
La réponse est plausible mais ne porte pas sur ce que vous demandiez [15]. Le plus souvent, c’est un manque de contexte ou d’instruction précise.
Solution : resserrez votre contexte. Reformulez la question en la rendant plus spécifique. Ajoutez un exemple de la réponse attendue si nécessaire.
Format non respecté : la bonne information, la mauvaise forme
Le contenu est correct mais la mise en forme ne correspond pas à ce que vous attendiez (une liste au lieu d’un tableau, un ton inadapté, une longueur excessive).
Solution : précisez le format de manière explicite et, idéalement, fournissez un exemple de la structure attendue [4].
La démarche reste la même : modifier un élément à la fois, observer l’effet, ajuster [1][4]. Changer trois paramètres simultanément rend impossible de savoir ce qui a amélioré ou dégradé le résultat.
7. Du prompt isolé au contexte continu : la suite du chemin
Maîtriser la rédaction d’un prompt est la porte d’entrée, pas le plafond. Dans les architectures modernes, le prompt unique cède la place à des systèmes où le contexte est maintenu, enrichi et orchestré sur plusieurs étapes [1].
Le context engineering (ingénierie du contexte) désigne cette approche systémique : au lieu de rédiger un prompt isolé, on construit un environnement complet pour le modèle, incluant de la mémoire persistante, des rôles définis sur la durée, des outils que le modèle peut appeler et des agents spécialisés qui collaborent [1]. Le prompt devient un composant dans un pipeline plus large.
Concrètement, deux horizons s’ouvrent :
- À court terme, les techniques de ce guide s’appliquent à chaque interaction avec un modèle de langage, que ce soit dans une interface de chat, un script d’automatisation ou une application intégrée.
- À moyen terme, si vous construisez un produit ou un processus autour de l’IA, le prompt n’est qu’un étage de l’architecture. L’orchestration, la gestion de la mémoire et la définition des rôles d’agent deviennent les leviers principaux [1][7].
Le craft du prompting demande de la précision, de l’itération, de la sensibilité au comportement du modèle et des cycles d’essai et d’erreur [1]. C’est une compétence qui se construit en pratiquant, un prompt à la fois.
Sources
- [1] Context Engineering From Prompts to Corporate Multi-Agent Architecture · V.V.Vishnyakova, Ph.D. · 2026 · preprint · arXiv:2603.09619
- [2] Building Generative AI Services with FastAPI A Practical Approach to Developing Context-Rich Generative AI Applications · livre · Amazon
- [3] Generative AI on Kubernetes Operationalizing Large Language Models · livre · Amazon
- [4] The AI Product Playbook Strategies, Skills, and Frameworks for the AI-Driven Product Manager · livre · Amazon
- [5] LLMOps Managing Large Language Models in Production · livre · Amazon
- [6] GenAI on Google Cloud Enterprise Generative AI Systems and Agents · livre · Amazon
- [7] Agentic AI for Engineers · livre · Amazon
- [8] Query-Centric Graph Retrieval Augmented Generation · Yaxiong Wu et al. · 2025 · preprint · arXiv:2509.21237
- [9] Case-Aware LLM-as-a-Judge Evaluation for Enterprise-Scale RAG Systems · Mukul Chhabra et al. · 2026 · preprint · arXiv:2602.20379
- [10] Hypothetical Documents or Knowledge Leakage? Rethinking LLM-based Query Expansion · Yejun Yoon et al. · 2025 · preprint · arXiv:2504.14175
- [11] SoK: Agentic Retrieval-Augmented Generation (RAG): Taxonomy, Architectures, Evaluation, and Research Directions · Saroj Mishra et al. · 2026 · preprint · arXiv:2603.07379
- [12] RJE: A Retrieval-Judgment-Exploration Framework for Efficient Knowledge Graph Question Answering with LLMs · Can Lin et al. · 2025 · preprint · arXiv:2510.01257
- [13] Beyond Chunks and Graphs: Retrieval-Augmented Generation through Triplet-Driven Thinking · Shengbo Gong et al. · 2025 · preprint · arXiv:2508.02435
- [14] TraceLLM: Leveraging Large Language Models with Prompt Engineering for Enhanced Requirements Traceability · Nouf Alturayeif et al. · 2026 · preprint · arXiv:2602.01253
- [15] Hands-On RAG for Production · Ofer Mendelevitch and Forrest Sheng Bao · livre · Amazon