
Nadia dirige le service comptabilité fournisseurs d’une PME de 200 personnes. La direction vient de lancer un mot d’ordre : « intégrer l’IA dans les processus métiers d’ici six mois ». Problème, dans son équipe, personne ne sait avec précision quelles tâches absorbent le plus de temps, lesquelles se répètent à l’identique, et lesquelles prêtent réellement à une automatisation intelligente.
Avant de parler d’IA, regardez vos mains travailler
L’erreur la plus fréquente quand une entreprise décide de déployer l’IA consiste à choisir un outil avant de comprendre le travail réel. On achète une plateforme, on configure un modèle de langage, et trois mois plus tard on découvre que l’IA automatise ce que personne ne faisait vraiment. Ou pire, elle automatise une tâche marginale en laissant intacte celle qui consomme 40 % du temps d’équipe.
Le task mining (extraction de tâches) désigne un ensemble de techniques qui visent à découvrir et analyser l’exécution concrète des tâches humaines en observant les interactions entre les employés et leurs logiciels [1]. Contrairement au process mining, qui reconstitue le flux global d’un processus métiers à partir des journaux d’événements des systèmes d’information, le task mining se place au niveau le plus granulaire : les clics, les copier-coller, les allers-retours entre fenêtres, les saisies manuelles [1]. Les trois principaux cas d’usage du task mining sont la découverte et l’optimisation des tâches, l’optimisation des ressources et de la main-d’œuvre, et l’automatisation des tâches [1].
La phase de découverte qui précède toute automatisation repose sur trois piliers : le process mining, le task mining et l’analyse de processus [2]. Sans cette phase, impossible d’identifier avec rigueur quel processus, et quelles parties de ce processus, méritent réellement d’être automatisés [3].
Nadia (persona fictif d’illustration) n’a pas besoin de devenir experte en task mining. Elle a besoin de comprendre ce que son équipe fait réellement, heure après heure, avant de décider quoi déléguer à une machine. C’est typiquement le rôle pouvant être attribué à un chef de projet IA (Cf. Recrutement d’un chef de projet IA)
Poser les yeux sur le terrain : les 5 signaux à capter dès cette semaine
Avant d’installer le moindre outil, commencez par observer. Voici cinq signaux concrets, visibles à l’œil nu dans n’importe quel service, qui indiquent qu’une tâche « crie » potentiellement l’automatisation.
1. Le copier-coller entre deux logiciels. Un employé ouvre un PDF, repère un numéro de facture, le recopie dans un tableur, puis le colle dans l’ERP (le logiciel intégré de gestion d’entreprise). Ce va-et-vient manuel est le signal le plus courant du task mining : l’interaction entre un humain et ses outils se répète à l’identique, sans valeur ajoutée de jugement [1][4].
2. La navigation frénétique entre fenêtres. Trois écrans ouverts, sept onglets, un allers-retours constant entre une boîte mail, un dossier partagé et un formulaire de saisie. Quand une tâche nécessite de jongler entre quatre applications pour produire un seul résultat, le problème n’est pas l’humain : c’est le manque d’intégration.
3. La saisie recopiée d’un document non structuré. Factures PDF, bons de commande scannés, contrats papier numérisés… Chaque fois qu’un employé extrait des informations d’un document pour les saisir dans un système, il effectue un travail de reconnaissance et de transcription que l’IA sait faire aujourd’hui à grande vitesse [5].
4. La règle « au doigt mouillé » devenue processus. Un chargé de recouvrement décide de relancer les factures au-dessus de 2 000 € au bout de 30 jours, mais en dessous de 500 € il attend 60 jours. Cette règle, jamais formalisée, se transmet oralement. Elle contient pourtant une logique décisionnelle extractible.
5. La file d’attente invisible. Des validations s’empilent dans une boîte mail partagée, personne ne sait qui doit traiter quoi en priorité. Le workflow n’existe que dans la tête de deux personnes. Quand l’une est absente, tout bloque.
Nadia passe une heure à observer trois collaborateurs volontaires. Résultat : elle repère immédiatement les signaux 1, 3 et 4. Son équipe passe près de 40 % de son temps à recopier des données de factures PDF dans l’ERP, selon une règle de priorité des paiements jamais écrite nulle part.
Capturer sans paralyser : la collecte légère de données de tâches
Observer à l’œil nu donne un premier aperçu, mais pour alimenter une décision d’IA, il faut des données un peu plus structurées. L’erreur serait de lancer un projet de collecte massif, avec des mois de screen recording et un déploiement d’outils invasifs. Ce n’est ni nécessaire, ni souhaitable au démarrage.
Automatisation de process : l'approche
Comment je le conçois concrètement : étapes, livrables et garde-fous.
Le task mining s’appuie sur plusieurs techniques de capture : l’enregistrement d’actions, le filtrage du bruit, la segmentation, la simplification, l’extraction de routines, la découverte de routines exécutables et la compilation [1]. En pratique, pour un premier sprint, trois approches suffisent.
Les mini-interviews ciblées (15 minutes)
Choisissez 3 à 5 personnes qui exécutent la même tâche. Demandez-leur de vous raconter, étape par étape, ce qu’elles font sur une journée type. Ne demandez pas « quel processus suivez-vous » (terme trop abstrait). Demandez : « Quand vous arrivez le matin, quelle est la première chose que vous ouvrez sur votre écran ? » Les détails concrets émergent vite.
Le screen recording volontaire sur un poste pilote
Installez un outil de capture d’écran sur un seul poste, pendant une semaine, avec le consentement explicite de l’employé. L’objectif n’est pas de fliquer, mais de documenter les séquences d’interactions entre l’humain et ses logiciels. Les UI logs (journaux d’interface utilisateur) constituent la matière première du task mining : ils enregistrent chaque clic, chaque frappe, chaque changement de fenêtre [1][4]. Lorsque les données sont collectées à partir de plusieurs sources, un défi supplémentaire apparaît : il faut les relier entre elles grâce à des identifiants, des noms d’utilisateur ou des mots-clés [1].
L’observation « en binôme »
Placez-vous à côté d’un collègue pendant une heure. Prenez des notes sur les allers-retours entre applications, les moments d’hésitation, les tâches qui déclenchent un soupir. C’est l’équivalent terrain du shadowing utilisé en recherche UX.
Règle d’or : la transparence totale. Informez l’équipe de l’objectif (comprendre le travail pour soulager la charge, pas pour supprimer des postes). Donnez un droit de veto sur ce qui est enregisté. Sans confiance, pas de données fiables.
Nadia teste le binôme sur deux matinées avec sa collaboratrice la plus ancienne, Sabrina. Elle découvre que Sabrina ouvre cinq logiciels différents pour traiter une seule facture, dont deux uniquement pour vérifier un numéro de TVA qu’elle pourrait trouver autrement.
Trier le signal du bruit : la grille de priorisation en 4 critères
Vous avez cartographié une douzaine de tâches. Certaines sont pénibles mais rares. D’autres sont fréquentes mais nécessitent un jugement humain fort. Comment choisir sur quoi concentrer l’effort d’IA ?
Avant tout déploiement d’automatisation (et pour limiter la résistance au changement), une évaluation de la valeur doit examiner si et dans quelle mesure l’automatisation profite à l’entreprise et à ses employés [3]. En parallèle, l’identification et la priorisation du problème constituent le premier point de décision clé de la gouvernance organisationnelle de toute technologie émergente [6].
Voici une grille simple, applicable en une heure avec l’équipe :
| Critère | Question à poser | Score (1 à 5) |
|---|---|---|
| Volume | Combien de fois par jour ou par semaine cette tâche est-elle exécutée ? | Plus c’est fréquent, plus le score est élevé |
| Répétitivité | La tâche suit-elle le même schéma à chaque exécution ? | Schéma identique : 5 / Schéma variable : 1 |
| Pénibilité ou coût d’erreur | Cette tâche provoque-t-elle des erreurs, des retards, de la frustration ? | Fort impact : 5 |
| Faisabilité IA | Les données sont-elles structurées ou extractibles (documents, tableaux, formulaires) ? | Données structurées : 5 / Jugement créatif : 1 |
Appliquons cette grille aux tâches repérées par Nadia :
| Tâche | Volume | Répétitivité | Pénibilité | Faisabilité IA | Total |
|---|---|---|---|---|---|
| Saisie de factures dans l’ERP | 5 | 5 | 4 | 4 | 18 |
| Vérification du numéro de TVA | 4 | 5 | 2 | 5 | 16 |
| Règle de priorité des paiements | 3 | 3 | 3 | 3 | 12 |
| Relance fournisseurs par e-mail | 2 | 3 | 2 | 4 | 11 |
| Réconciliation bancaire | 3 | 2 | 5 | 2 | 12 |
Deux tâches sortent du lot : la saisie de factures (score 18) et la vérification de TVA (score 16). Ce sont elles que Nadia cible en priorité. La réconciliation bancaire, bien que pénible, obtient un score de faisabilité IA faible, car elle repose sur des rapprochements contextuels complexes, variables d’un mois sur l’autre. La relance fournisseurs, quant à elle, est trop rare pour justifier un investissement immédiat.
Relier chaque tâche au bon type d’IA : le mappage sans buzzword
Les tâches sont priorisées. Reste à les associer à la bonne capacité d’IA. Pas besoin de jargon technique : les modèles d’IA actuels offrent un ensemble de capacités identifiables et compréhensibles [5].
| Capacité IA | En langage clair | Exemple de tâche correspondante |
|---|---|---|
| Extraction de données | Lire un document (PDF, image, scan) et en sortir des informations structurées | Extraire le montant, la date et le numéro de TVA d’une facture |
| Classification | Catégoriser un texte, un e-mail, un document selon des règles ou des patterns | Trier les e-mails fournisseurs par type de demande [5] |
| Génération de texte | Rédiger un texte à partir d’instructions ou d’un contexte | Rédiger un e-mail de relance standardisé [5] |
| Interprétation contextuelle | Comprendre le sens d’une information en fonction du contexte, puis prendre une décision | Décider si une facture correspond à une commande existante [5] |
| Utilisation d’outils | Appeler un autre logiciel pour récupérer une information ou effectuer une action | Aller chercher le numéro de TVA d’un fournisseur dans une base publique [5] |
Pour la saisie de factures de Nadia, la combinaison est claire : extraction de données (lire le PDF) + interprétation contextuelle (vérifier la cohérence montant/quantité) + utilisation d’outils (pré-remplir les champs de l’ERP). Trois capacités enchaînées, une seule pipeline.
Pour la vérification de TVA : extraction de données (lire le numéro sur la facture) + utilisation d’outils (interroger une base publique de vérification de TVA). Deux étapes, entièrement automatisables.
Le système d’IA qui en résulte n’a pas besoin d’être sophistiqué. Il combine des composants simples, chacun spécialisé dans une étape. L’essentiel est que le pipeline complet reproduise fidèlement ce que Sabrina faisait en 20 minutes, mais en quelques secondes.
Le sprint 30 jours : passer de la cartographie au premier prototype
Pas besoin d’un projet de transformation digitale de 18 mois. Voici un plan d’audit IA en quatre semaines, chaque semaine avec un objectif unique et une sortie vérifiable.
Un besoin en automatisation de process ?
Configurez votre projet et recevez un devis clair sous 24h, sans engagement.
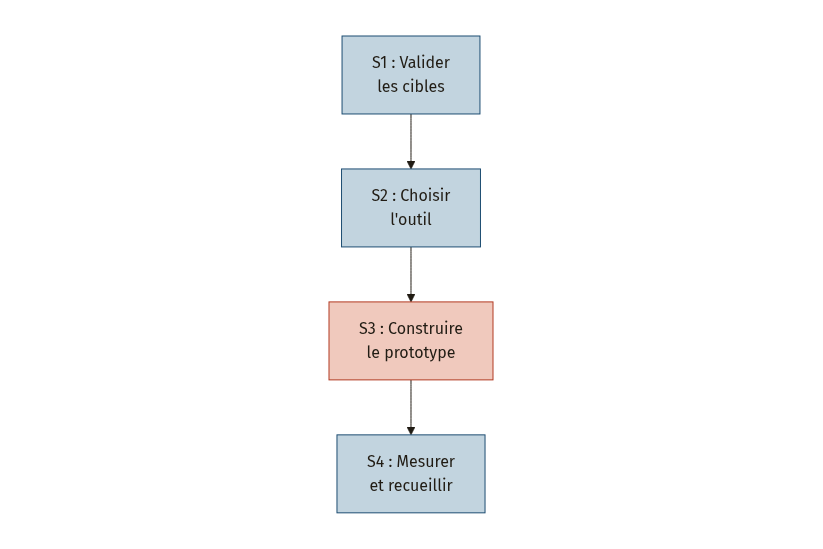
Semaine 1 : Valider les cibles avec l’équipe. Présentez la grille de priorisation à l’équipe. Confrontez vos observations terrain avec leur vécu quotidien. Demandez : « Est-ce que cette tâche vous semble bien représentée ? Ai-je raté quelque chose ? » Cette étape de validation est essentielle. Les résultats de déploiement de la plateforme Empsing/MSAM (une solution d’IA d’entreprise) indiquaient un taux de réduction d’effort de 94,3 %, mais le feedback utilisateurs révélait que 25 % d’entre eux estimaient que la plateforme nécessitait un effort supplémentaire d’adaptation [7]. L’outil le plus performant ne sert à rien s’il ne correspond pas au travail réel.
Sortie S1 : une liste de 2 à 3 tâches cibles, validées par l’équipe.
Semaine 2 : Choisir l’outil sans sur-ingénierie. Pour l’extraction de données à partir de factures, des solutions d’OCR (reconnaissance optique de caractères) couplées à des modèles de langage sont accessibles via des API. Pas besoin de recruter un data scientist : des plateformes no-code ou low-code permettent de connecter un modèle d’IA à un formulaire de saisie en quelques heures. L’analyse des opportunités d’automatisation montre cependant que les fournisseurs de solutions couvrent inégalement les besoins : évaluez spécifiquement la couverture de la gestion des exigences (« requirements management ») et du monitoring [3].
Sortie S2 : un outil choisi, un accès test obtenu.
Semaine 3 : Construire le prototype sur un cas limité. Concentrez-vous sur une seule tâche (la saisie de factures) et un volume réduit (20 à 30 factures). Branchez l’extraction de données sur les champs de l’ERP. Testez les résultats avec Sabrina. Corrigez les erreurs. L’itération rapide sur un périmètre étroit vaut infiniment mieux qu’un déploiement large non testé.
La conception d’outils d’IA en entreprise gagne à définir des jalons d’apprentissage progressifs : plutôt que de demander aux utilisateurs de maîtriser l’outil d’un coup, proposez des mini-succès qui construisent la confiance [8]. Le premier prototype ne doit pas tout faire. Il doit fonctionner sur un cas précis, visible, vérifiable.
Sortie S3 : un prototype fonctionnel sur 20 à 30 factures, avec un taux d’erreur mesuré.
Semaine 4 : Mesurer le gain et recueillir le feedback. Comparez le temps de traitement avant et après. Calculez le taux d’erreur. Demandez à l’équipe ce qu’elle en pense. Identifiez ce qui bloque, ce qui surprend, ce qui plaît.
| Métrique | Avant IA | Après prototype | Gain |
|---|---|---|---|
| Temps par facture | 8 min | 2 min (vérification manuelle incluse) | 75 % en moins |
| Erreurs de saisie | environ 5 % | environ 1 % | 80 % en moins |
| Satisfaction équipe | Non mesurée | Feedback ouvert | En cours |
Ces chiffres ne sont pas universels : ils reflètent le scénario de Nadia. L’important n’est pas le pourcentage exact, c’est le fait d’avoir mesuré quelque chose de concret avant et après. Isoler la contribution propre de l’IA aux améliorations observées reste un défi méthodologique : de multiples facteurs influencent les résultats simultanément [9]. D’où l’importance de mesurer sur un périmètre étroit et contrôlé.
Sortie S4 : un rapport de résultats (une page suffit), et une décision : poursuivre, ajuster ou abandonner.
Ne pas lâcher : instaurer la boucle d’observation continue
Le plus gros piège du task mining n’est pas de mal le faire. C’est de le faire une fois, puis d’oublier.
Les techniques d’enregistrement d’actions, de filtrage du bruit, de segmentation et d’extraction de routines s’inscrivent dans un cycle continu d’observation et d’amélioration [1]. Lorsque des robots RPA (automatisation robotique des processus, c’est-à-dire des logiciels qui exécutent des tâches répétitives à la place d’un humain) sont déployés, le process mining permet de les surveiller en continu, de détecter les cas non standard et d’améliorer l’interaction entre systèmes, robots et personnes [1]. En parallèle, la phase d’évaluation de l’IA dans les processus métiers peut s’appuyer sur des techniques de process mining étendues, comme la méthodologie OCPM2 (process mining centré sur les objets) pour analyser comment l’IA a transformé la scalabilité du processus [10].
Concrètement, instaurer la boucle continue repose sur trois rituels légers :
1. La revue mensuelle d’une heure. Réunissez l’équipe autour d’une question simple : « Quelle tâche vous pèse le plus en ce moment ? » Notez-la. Comparez avec le mois précédent. Si la même tâche revient, elle mérite une investigation. Si de nouvelles apparaissent, l’environnement a changé et vos automatisations doivent suivre. La recherche montre que la diversité des tâches de travail évolue avec la numérisation : ce qui était complexe hier devient standard, et de nouvelles complexités émergent [11].
2. Le suivi des indicateurs de performance. Définissez des métriques simples et suivez-les. Le cadre des indicateurs de performance dans les systèmes automatisés repose sur trois niveaux : un objectif mesurable (par exemple, « traiter 95 % des factures en moins de 2 minutes »), un accord de niveau de service (« maintenir le taux d’erreur sous 2 % »), et un indicateur clé de performance suivi mensuellement (« temps moyen de traitement par facture ») [12]. Pas besoin de tableaux de bord complexes : un tableur partagé avec trois chiffres mis à jour chaque mois suffit au démarrage.
3. Le feedback ouvert des utilisateurs. Les outils d’IA en entreprise ne sont adoptés durablement que si les utilisateurs progressent par étapes successives et observent leurs collègues les utiliser [8]. Créez un canal simple (un formulaire, un canal de discussion) où chacun peut signaler un dysfonctionnement, suggérer une amélioration ou partager un usage inattendu de l’outil.
Le vrai gain de l’IA ne vient pas du déploiement initial. Il vient de l’amélioration continue que le task mining rend possible : observer, ajuster, réobserver. Six mois après son premier sprint, Nadia n’a pas « mis l’IA dans ses processus ». Elle a mis en place une habitude de regarder son travail autrement, et l’IA n’est devenue que l’outil qui traduit ce regard en action.
Sources
- [1] Robotic Process Automation Using Process Mining $\unicode{x2013}$ A Systematic Literature Review · preprint · arXiv:2204.00751
- [2] Hyper-automation-The next peripheral for automation in IT industries · preprint · arXiv:2305.11896
- [3] What is Business Process Automation Anyway? · preprint · arXiv:2506.10991
- [4] Identifying candidate routines for Robotic Process Automation from unsegmented UI logs · preprint · arXiv:2008.05782
- [5] Building Applications with AI Agents Designing and Implementing Multiagent Systems · livre · Amazon
- [6] Organizational Governance of Emerging Technologies: AI Adoption in Healthcare · preprint · arXiv:2304.13081
- [7] Designing Multi-Step Action Models for Enterprise AI Adoption · preprint · arXiv:2403.14645
- [8] Beyond Training: How Workers Discover Value in Enterprise AI · preprint · arXiv:2502.13281
- [9] The Risk-Adjusted Intelligence Dividend: A Quantitative Framework for Measuring AI Return on Investment Integrating ISO 42001 and Regulatory Exposure · preprint · arXiv:2511.21975
- [10] AI-Enhanced Business Process Automation: A Case Study in the Insurance Domain Using Object-Centric Process Mining · preprint · arXiv:2504.17295
- [11] Digital Transformation in Switzerland: The Current State and Expectations · preprint · arXiv:2412.12784
- [12] LLMOps Managing Large Language Models in Production · livre · Amazon


