
Vos équipes utilisent des dizaines d’outils informatiques au quotidien, mais personne ne sait vraiment décrire comment un processus se déroule d’un bout à l’autre. Les schémas officiels dans la documentation interne ne reflètent pas ce qui se passe réellement sur les écrans. Et pourtant, c’est précisément cette réalité terrain qu’il faut cartographier avant d’introduire la moindre intelligence artificielle. Le process mining, l’ensemble de techniques qui extrait automatiquement le déroulé réel des opérations à partir des données informatiques, est le levier concret pour y parvenir.
1. Captez ce que vos équipes font vraiment (avant toute discussion sur l’IA)
Le problème de départ
La grande majorité des systèmes d’information ne consignent pas les données d’exécution sous une forme directement exploitable pour analyser les processus [1]. Les logs existent, mais ils sont fragmentés, hétérogènes, et ne racontent pas une histoire cohérente de bout en bout. Avant de parler d’automatisation, il faut donc construire les fondations : constituer un event log, c’est-à-dire un fichier structuré qui retrace chronologiquement chaque action réalisée dans le cadre d’un processus.
Les trois champs minimum d’un event log exploitable
Toute donnée événementielle doit comporter au moins trois propriétés pour être utilisable [2] :
| Propriété | Ce que c’est | Exemple concret |
|---|---|---|
| Horodatage (timestamp) | Le moment exact où l’action s’est produite | 2025-03-15T09:14:22 |
| Libellé d’activité (activity label) | Le nom de l’étape réalisée | Validation commande, Approbation manager |
| Identifiant de cas (case ID) | Le numéro unique qui rattache l’événement à une instance du processus | CMD-2025-04521 |
Sans ces trois éléments, aucun algorithme de process mining ne peut reconstituer le fil d’un processus. Le format de référence pour consigner ces données est le standard XES (eXtensible Event Stream), développé par l’IEEE Task Force on Process Mining et reconnu par la communauté industrielle et académique [2].
D’où viennent ces données ?
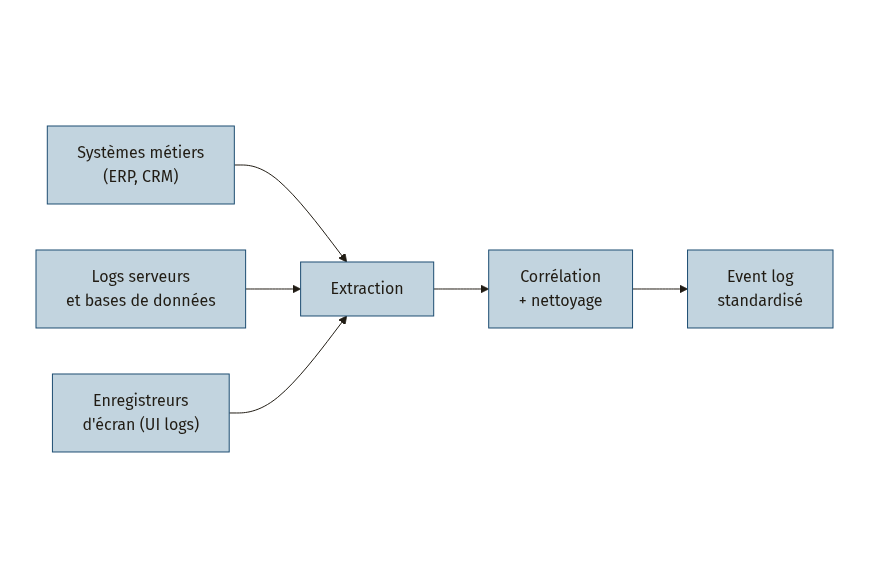
Trois sources principales alimentent l’event log [3][1] :
- Les systèmes métiers (ERP, CRM, plateformes de workflow) : ils contiennent des traces transactionnelles, mais souvent sous un format propriétaire qui nécessite un travail de transformation.
- Les logs techniques (bases de données, serveurs d’application) : riches en informations, mais sans sémantique métier directe. Il faut les interpréter.
- Les UI logs (enregistreurs d’actions au niveau de l’interface utilisateur) : ils capturent les clics, les saisies, les navigactions entre écrans. C’est la source la plus proche du travail réel de l’opérateur, particulièrement précieuse pour identifier des routines répétitives [3]. Les principaux attributs capturés par les outils industriels incluent le type d’action, l’élément ciblé, la hiérarchie de l’interface, l’application, la valeur saisie et l’horodatage [3].
Ce que « préparer les données » veut dire concrètement
Le passage du log brut à un event log exploitable implique trois étapes [1] :
- Extraction (data extraction) : récupérer les données depuis les différentes sources, souvent avec des requêtes SQL, des connecteurs ETL ou des scripts dédiés.
- Corrélation (correlation) : relier les événements entre eux pour reconstituer les cas. Par exemple, associer une saisie dans l’écran A avec la validation dans l’écran B grâce à un numéro de dossier commun.
- Abstraction (abstraction) : donner un sens métier aux données brutes. Transformer un code technique (
STATUS_CD = 42) en libellé compréhensible (Commande validée).
Action immédiate : identifiez un processus cible et listez les systèmes impliqués. Demandez à votre équipe SI de vous fournir un extrait de logs bruts de ces systèmes sur une période représentative (au moins un mois). Vérifiez si les trois champs minimum (horodatage, activité, identifiant de cas) sont présents. Si ce n’est pas le cas, priorisez la mise en place de ces champs avant tout projet d’IA.
2. Triez vos processus avec une grille simple pour éviter de perdre du temps
Pourquoi tous les processus ne se prêtent pas à l’IA
L’introduction de l’Intelligence Aartificielle n’a de sens que sur des processus qui présentent un potentiel réel de gain (cf. Cartographie des processus). Déployer un modèle de machine learning sur un processus exécuté deux fois par mois, impliquant trois personnes et aucune règle répétitive, c’est investir des ressources sans retour mesurable. Le process mining permet justement de mesurer objectivement les caractéristiques de chaque processus avant de décider quoi automatiser [3].
La grille d’évaluation à quatre critères
| Critère | Ce que le process mining mesure | Seuil indicatif d’opportunité |
|---|---|---|
| Volume | Nombre de cas par période | Élevé (centaines/milliers par mois) |
| Durée | Temps moyen et extrêmes par tâche et par cas total | Long, avec des écarts importants entre cas |
| Répétitivité des règles | Proportion de cas suivant le même chemin | > 80 % de cas suivant le chemin dominant |
| Taux de déviation | Écarts entre le modèle attendu et l’exécution réelle | Déviations fréquentes = potentiel d’amélioration ou processus trop instable pour automatiser tel quel |
Le process mining fournit directement ces métriques à partir de l’event log sans nécessiter d’hypothèses a priori sur le processus [1]. La découverte automatique du processus (process discovery) génère un modèle visuel du déroulé réel, tandis que l’analyse de durée (duration analysis) identifie les tâches et les cas qui consomment le plus de temps [3].
Comment lire un modèle découvert
Le résultat typique de la découverte de processus est un graphe de flux direct (directly follows graph) : chaque nœud représente une activité, chaque arc représente une transition observée entre deux activités, avec la fréquence annotée [4]. En lisant ce graphe, vous voyez en un coup d’œil :
- Le chemin dominant (la séquence d’activités la plus fréquente).
- Les boucles (une activité qui revient plusieurs fois dans le même cas : signe de reprise, correction ou rejet).
- Les chemins rares (cas atypiques qui peuvent indiquer des erreurs ou des exceptions métier).
Action immédiate : pour chaque processus candidat, calculez le nombre de cas sur les 6 derniers mois et le temps médian de traitement. Comparez-le au temps idéal (si vous le connaissez). L’écart entre les deux est votre premier indicateur de maturité pour l’IA.
3. Confrontez le réel au théorique, et écoutez ce que les écarts vous disent
Pourquoi automatiser un processus cassé accélère les problèmes
Si un processus comporte des étapes inutiles, des allers-retours entre services, ou des contrôles redondants, automatiser ce processus avec la RPA (Robotic Process Automation) ou l’IA revient à accélérer un dysfonctionnement. Le conformance checking, c’est-à-dire la vérification de conformité entre un modèle de référence et l’exécution réelle, permet de diagnostiquer précisément où le processus dévie [1][5].
Ce que le conformance checking révèle concrètement
En pratique, la vérification de conformité superpose le modèle attendu (par exemple, le processus tel que documenté dans votre système de workflow) et l’event log réel. Le résultat met en évidence [5] :
- Les étapes sautées : une validation qui devait être effectuée mais ne l’a pas été.
- Les étapes supplémentaires : des actions réalisées qui n’avaient pas été prévues dans le modèle.
- Les transpositions : des étapes exécutées dans le désordre.
- Les boucles anormales : un dossier qui revient trois fois à la même étape d’approbation.
Le système de Camunda, par exemple, permet d’appliquer ces techniques de conformance checking directement sur les processus exécutés dans son moteur BPMN, en croisant le modèle et les logs d’exécution stockés dans la base de données [6].
L’analyse organisationnelle : qui fait quoi
Au-delà du déroulé technique, le mining organisationnel (organizational mining) révèle les interactions entre les acteurs : qui délègue à qui, quel service crée des goulots d’étranglement, quelles compétences sont sollicitées à quel moment [2]. Cette analyse produit notamment des modèles de réseau social (social network models) qui visualisent les flux de travail entre personnes et équipes [4].
Action immédiate : lancez un conformance checking sur votre processus cible. Si le taux de déviation dépasse 30 % des cas, il y a fort à parier que le processus lui-même doit être stabilisé avant d’y introduire de l’IA. Commencez par éliminer les étapes inutiles et les boucles parasites.
4. Transformez vos event logs en données dont l’IA peut apprendre
Du log d’événements au jeu d’entraînement
L’event log issu du process mining est une ressource structurée, mais il n’est pas directement un jeu de données (dataset) pour entraîner un modèle de machine learning. Le passage de l’un à l’autre exige un travail d’enrichissement sémantique et de structuration [1].
Automatisation de process : l'approche
Comment je le conçois concrètement : étapes, livrables et garde-fous.
Ce travail de préparation comprend concrètement
- Enrichir les événements avec du contexte métier : croiser l’event log avec des données de référence (catalogue produits, grille tarifaire, organigramme) pour ajouter des variables descriptives à chaque cas.
- Créer des variables dérivées : à partir de l’event log, calculer des indicateurs agrégés par cas (nombre total d’étapes, durée totale, nombre de reprises, nombre d’acteurs impliqués) qui serviront de features (variables d’entrée) pour un modèle prédictif.
- Standardiser au format XES : pour garantir la compatibilité avec les outils de process mining et faciliter les échanges entre équipes [2][7].
- Nettoyer et filtrer : supprimer les doublons, les événements sans identifiant de cas, les anomalies de saisie. La bibliothèque open-source logprep4pm, construite sur Pandas, fournit des fonctionnalités de prétraitement réutilisables spécifiquement conçues pour les event logs de process mining [4].
Le standard XES : un interlingua technique
Le format XES (eXtensible Event Stream), normalisé par l’IEEE, impose une structure XML dans laquelle chaque event log contient des traces (une trace = un cas), chaque trace contient des événements, et chaque événement porte des attributs (horodatage, activité, ressource, etc.) [2][7]. Cette standardisation est essentielle pour pouvoir utiliser indifféremment les outils PM4Py, ProM, Disco ou d’autres plateformes de process mining.
Action immédiate : une fois votre event log constitué et nettoyé, exportez-le au format XES. Identifiez trois à cinq variables dérivées pertinentes pour votre cas métier (par exemple : « nombre de validations avant accord », « durée entre première saisie et clôture », « nombre d’intervenants distincts »). Ces variables constitueront la base d’un premier modèle prédictif ou de classification.
5. Concevez dès le départ un pilotage mixte humains et bots
RPA vs IPA : deux approches, deux ambitions
La RPA (Robotic Process Automation) se concentre sur la création de robots logiciels qui exécutent une tâche répétitive à la place d’un humain : copier un numéro d’un écran vers un autre, remplir un formulaire, extraire un montant d’un PDF. L’IPA (Intelligent Process Automation) va plus loin : elle orchestre la coordination entre humains et multiples bots sur l’ensemble du cycle de vie d’un processus, depuis l’identification des opportunités d’automatisation jusqu’au monitoring continu de la performance et au réentraînement des bots [8].
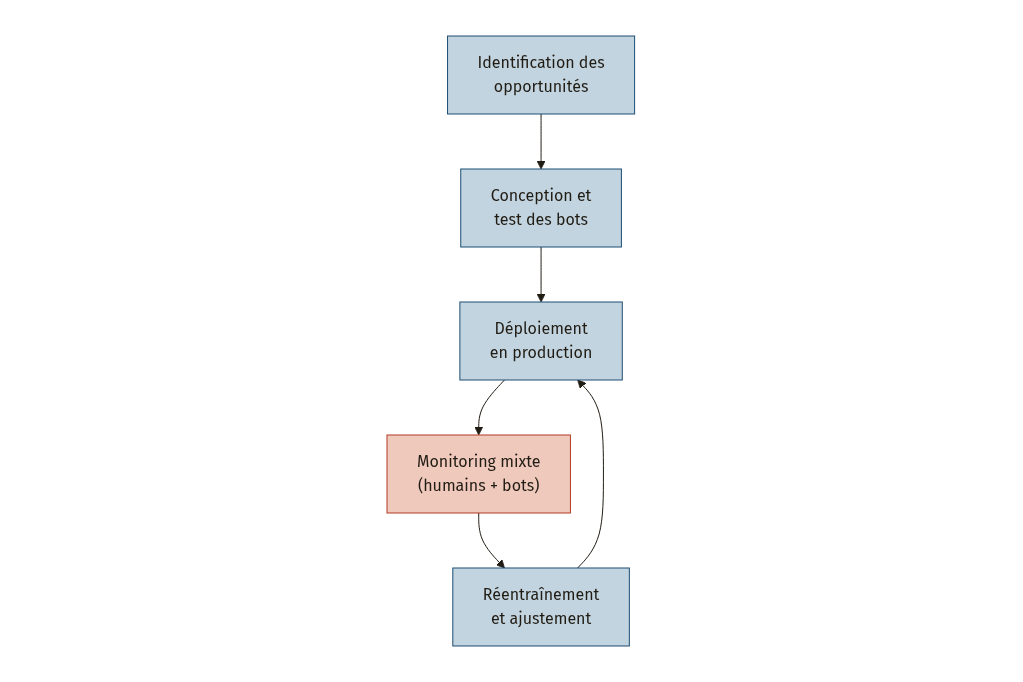
Le cycle complet de l’IPA [8] inclut une phase de monitoring continu (l’étape D sur le schéma) qui est précisément là où le process mining intervient une seconde fois : non plus pour découvrir le processus, mais pour surveiller la performance du système hybride humains-bots en permanence.
Les « digital shadows » du processus
Dans le cadre du Cluster of Excellence « Internet of Production » (IoP), des chercheurs travaillent sur la création d’ombres numériques (digital shadows) des processus opérationnels [5]. L’idée : maintenir en temps réel une représentation actualisée du processus qui permet de détecter immédiatement toute anomalie, dérive ou opportunité d’amélioration. Trois axes de recherche avancent cette vision [5] :
- Le process mining comparatif (comparative process mining) : comparer les variants d’un même processus entre sites, entre périodes, entre gammes de produits.
- Le process mining centré sur les objets (object-centric process mining) : traiter les processus impliquant différents types d’objets (commandes, factures, bons de livraison) qui interagissent, au lieu de forcer un seul identifiant de cas.
- Le process mining prospectif (forward-looking process mining) : explorer des questions « et si ? » (What if?) pour anticiper l’impact de changements organisationnels ou technologiques.
IPA et conformité réglementaire
L’introduction de bots dans un processus soumis à des contraintes réglementaires (finance, santé, administration) impose un suivi de conformité rigoureux. Des évaluations régulières de conformité doivent être menées avant chaque déploiement ou mise à jour significative [9]. Si les processus de contrôle de version révèlent un événement de non-conformité, des mesures correctives doivent être déclenchées immédiatement [9].
Action immédiate : avant de déployer un bot, définissez les métriques de monitoring que vous suivrez post-déploiement (taux de succès, temps de traitement, nombre d’exceptions remontées à un humain). Prévoyez un tableau de bord qui superpose les performances du bot et les indicateurs du processus global, pas seulement le bot isolé.
6. Gagnez la confiance des équipes par des micro-expérimentations visibles
Le facteur humain est souvent le point de rupture
Les études empiriques sur l’adoption d’outils d’IA au quotidien montrent que la confiance se construit par l’expérimentation et par la compréhension des limites de l’outil [10]. Les utilisateurs développent ce que les chercheurs appellent des théories populaires (folk theories) sur le fonctionnement de l’IA : des représentations mentales, souvent simplifiées, qui guident leur façon d’interagir avec l’outil [10].
Un besoin en automatisation de process ?
Configurez votre projet et recevez un devis clair sous 24h, sans engagement.
Ce qui construit (ou détruit) la confiance
Les travaux d’observation des pratiques utilisateurs identifient des schémas récurrents [10] :
Facteurs qui construisent la confiance :
– Expérimenter volontairement avec l’outil (intentional experimentation).
– Constater des cas de succès concrets et reproductibles.
– Comprendre où l’outil s’arrête (savoir quand l’IA n’est pas fiable).
– Tester en environnement contrôlé avant de généraliser.
– Corriger les erreurs de l’IA soi-même (le fixing renforce la compréhension).
Facteurs qui érodent la confiance :
– Des attentes initiales irréalistes sur les capacités de l’outil.
– L’absence d’accompagnement dans la prise en main (onboarding).
– L’incapacité à valider les suggestions de l’IA par des références externes.
– Le sentiment de perdre le contrôle quand l’IA prend trop de décisions.
Protocole d’expérimentation progressive
Plutôt que de déployer l’IA sur l’ensemble d’un processus en un coup, la meilleure approche consiste à procéder par micro-expérimentations [10] :
- Choisir un périmètre étroit : faire un task mining, et se concentrer sur une seule tâche, une seule équipe, un seul type de cas.
- Rendre les résultats visibles : chaque participant doit pouvoir voir ce que l’IA a proposé, ce qu’il a accepté ou refusé, et pourquoi.
- Laisser tester et corriger : le droit de contredire l’IA est essentiel pour que l’utilisateur développe un calibrage réaliste de ses capacités.
- Élargir progressivement : n’ajouter de la complexité (plus de cas, plus d’équipes) que lorsque la confiance est établie sur le périmètre initial.
Action immédiate : identifiez un pilote volontaire (une équipe, une tâche répétitive, un périmètre limité). Présentez les résultats du process mining aux participants avant même de parler d’IA : montrez-leur le graphe de leur propre processus réel. Ce premier « miroir » crée l’adhésion et ouvre le dialogue sur ce qui pourrait être automatisé.
7. Bouclez : du monitoring à l’amélioration continue pilotée par les données
L’intégration de l’IA n’est pas un projet à date de fin
Un constat revient dans les études d’implémentation : les organisations déploient l’IA à un rythme soutenu, mais peinent à en capturer de la valeur durable [11]. Elles manquent de cadres stratégiques et d’imagination opérationnelle pour reconfigurer leurs flux de travail et leurs priorités de façon à ce que l’IA délivre son potentiel transformateur de manière responsable [11]. La solution : inscrire l’IA dans un cycle permanent d’observation, mesure et ajustement.
Le cycle d’amélioration continue
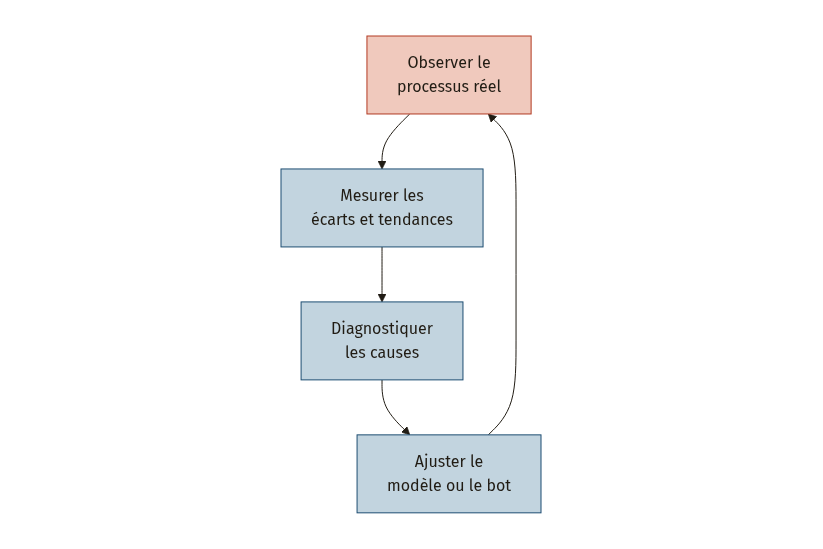
Ce cycle s’appuie sur trois capacités du process mining post-déploiement [3][5] :
- Le monitoring continu : comparer en permanence l’exécution réelle (humaine et automatisée) au modèle de référence, pour détecter toute dérive dès qu’elle apparaît.
- La comparaison de variants : mesurer les différences de performance entre sites, entre équipes, avant et après l’introduction de l’IA, ou entre versions successives d’un bot.
- L’exploration prospective : modéliser l’impact de changements organisationnels ou technologiques avant de les mettre en œuvre (What if?) [5].
Les cadres de préparation existants
Plusieurs travaux proposent des modèles structurés pour évaluer la préparation d’une organisation à l’IA avant même de lancer un projet [12]. Le modèle de maturité dit AI Readiness Framework [12] et le Task Automation Index [13] offrent des grilles d’évaluation qui, bien qu’issues de cadres académiques, se déclinent en checklists opérationnelles : niveau de maturité des données, compétences disponibles, gouvernance en place, appétence culturelle pour l’automatisation.
Le Task Automation Index [13] propose une approche pratique pour évaluer systématiquement chaque tâche et l’optimiser en vue de l’intégration de l’IA. Sa limite reconnue est qu’il repose sur une conceptualisation théorique initiale qui nécessite une validation empirique dans des contextes réels et variés [13].
Ce que le monitoring réglementaire exige
Pour les systèmes d’IA déployés en environnement contraint, le suivi continu ne concerne pas seulement la performance : il inclut la conformité réglementaire. Des évaluations régulières de conformité doivent être planifiées tout au long du cycle de vie du système d’IA [9]. Si le contrôle de versions révèle un événement de non-conformité, l’équipe responsable doit immédiatement déclencher des mesures correctives [9].
Action immédiate : avant même le premier déploiement, définissez votre tableau de bord de suivi post-déploiement. Listez les 5 indicateurs que vous suivrez chaque semaine (par exemple : taux de cas traités par le bot, taux d’exceptions remontées à un humain, temps médian de traitement, nombre de déviations détectées par le conformance checking, satisfaction des utilisateurs). Ce tableau de bord est votre boussole d’amélioration continue.
Synthèse opérationnelle : la séquence en 7 étapes
| Étape | Objectif | Livrable concret |
|---|---|---|
| 1. Capturer | Constituer l’event log avec les 3 champs minimum | Fichier XES sur un processus cible |
| 2. Trier | Évaluer les processus candidats à l’IA | Grille de scoring (volume, durée, répétitivité, déviations) |
| 3. Confronter | Comparer le réel au théorique | Rapport de conformance checking avec taux de déviation |
| 4. Structurer | Transformer le log en données exploitables par l’IA | Dataset enrichi avec variables dérivées |
| 5. Orchestrer | Concevoir le modèle humains-bots | Architecture IPA avec métriques de monitoring |
| 6. Expérimenter | Tester sur un périmètre étroit avec des volontaires | Résultats visibles du pilote, retours utilisateurs |
| 7. Boucler | Inscrire l’IA dans un cycle d’amélioration continue | Tableau de bord de suivi hebdomadaire |
Chacune de ces étapes s’appuie sur des données réelles, pas sur des hypothèses. Le process mining ne remplace pas le jugement métier : il lui fournit le miroir objectif dont il a besoin pour décider quoi automatiser, comment, et à quel rythme.
Sources
- [1] Conceptual Model with Built-in Process Mining · preprint · arXiv:2103.16956
- [2] Business Process Mining · preprint · arXiv:1607.00607
- [3] Robotic Process Automation Using Process Mining $\unicode{x2013}$ A Systematic Literature Review · preprint · arXiv:2204.00751
- [4] Using Process Mining to Improve Digital Service Delivery · preprint · arXiv:2409.05869
- [5] Removing Operational Friction Using Process Mining: Challenges Provided by the Internet of Production (IoP) · preprint · arXiv:2107.13066
- [6] An Open-Source Integration of Process Mining Features into the Camunda Workflow Engine: Data Extraction and Challenges · preprint · arXiv:2009.06209
- [7] SOPA: A Framework for Sustainability-Oriented Process Analysis and Re-design in Business Process Management · preprint · arXiv:2405.01176
- [8] From Robotic Process Automation to Intelligent Process Automation: Emerging Trends · preprint · arXiv:2007.13257
- [9] Putting AI Ethics into Practice: The Hourglass Model of Organizational AI Governance · preprint · arXiv:2206.00335
- [10] Investigating and Designing for Trust in AI-powered Code Generation Tools · preprint · arXiv:2305.11248
- [11] The Architecture of AI Transformation: Four Strategic Patterns and an Emerging Frontier · preprint · arXiv:2509.02853
- [12] From Challenge to Change: Design Principles for AI Transformations · preprint · arXiv:2512.05533
- [13] The Foundations of Computational Management: A Systematic Approach to Task Automation for the Integration of Artificial Intelligence into Existing Workflows · preprint · arXiv:2402.05142


