
L’automatisation robotique des processus (RPA) exécute des tâches répétitives selon des règles figées : copier un champ d’un tableur vers un logiciel, envoyer un email quand une condition est remplie, trier des documents par type. Elle transforme déjà la productivité de milliers d’entreprises, mais elle s’arrête net dès qu’un processus exige du jugement, de l’interprétation ou de l’adaptation au contexte. L’automatisation intelligente des processus (IPA) franchit ce mur en intégrant l’intelligence artificielle directement dans les flux de travail, permettant aux systèmes de lire des documents non structurés, de prendre des décisions contextuelles et de s’améliorer au fil de l’usage.
De l’automatisation aveugle à l’automatisation intelligente
Ce que le RPA sait faire… et où il s’arrête
Le RPA a ouvert la voie en automatisant des tâches administratives répétitives : saisie de données, extraction de champs, routage de formulaires. L’outil imite les gestes d’un opérateur humain sur un écran, sans comprendre le contenu qu’il manipule. C’est un robot exécutant des scripts, pas un agent capable de raisonner [1].
Le problème : la plupart des processus métiers réels ne sont pas des scripts. Un contrat à analyser, une réclamation client à interpréter, un bon de commande rédigé en langage naturel, une anomalie à diagnostiquer dans un flux de données… Ces tâches demandent de l’interprétation, du contexte, parfois de la créativité. Le RPA classique n’y touche pas.
L’IPA : la convergence de trois familles de technologies
L’IPA combine :
- L’apprentissage automatique (machine learning), qui permet au système de détecter des patterns dans des données historiques et de généraliser à de nouveaux cas.
- Le traitement du langage naturel (NLP), qui donne au système la capacité de lire, comprendre et générer du texte humain.
- L’orchestration intelligente, qui coordonne plusieurs outils et modèles dans un flux unifié, de la collecte de données à la prise de décision.
Selon l’enquête d’IBM Research sur le passage du RPA à l’IPA, cette convergence constitue un véritable point d’inflexion dans l’automatisation des processus métiers, pas une simple évolution incrémentale [1].
L’hyper-automatisation comme méthode globale
Le concept d’hyper-automatisation pousse la logique plus loin : il ne s’agit pas d’automatiser une tâche isolée, mais de cartographier, analyser et automatiser des processus entiers en combinant RPA, intelligence artificielle et orchestration de flux de travail [2]. La méthodologie passe par trois phases :
- Découverte : process mining (analyse automatisée des journaux de systèmes d’information pour reconstituer les flux réels) et task mining (observation des actions de l’utilisateur sur son poste de travail) pour identifier les véritables parcours et leurs goulots.
- Modélisation : représentation formelle des étapes, des règles métier et des points de décision.
- Implémentation : déploiement de l’automatisation sur les étapes identifiées, en combinant RPA et IA.
La phase de découverte est souvent négligée, alors qu’elle fournit le socle factuel indispensable. Automatiser un processus tel qu’il est décrit dans la documentation interne, sans vérifier qu’il correspond au processus réel, est une erreur courante et coûteuse [2].
L’IA générative accélère le mouvement
L’arrivée des modèles de langage de grande taille (LLM, ou large language models) et des modèles de fondation (foundation models) change radicalement la donne. Ces modèles, capables de comprendre et générer du texte, du code et même des raisonnements multi-étapes, ouvrent la porte à l’automatisation de tâches jusqu’ici inaccessibles : analyse de contrats, rédaction de rapports, résolution de problèmes complexes.
Le cadre proposé par des chercheurs de Stanford pour l’automatisation des processus d’entreprise avec les modèles de fondation formalise cette approche : à partir de procédures opérationnelles standard (les SOP, documents décrivant pas à pas les étapes d’un processus) et de démonstrations humaines, le système apprend à exécuter un flux de travail complet, état par état et action par action [3]. Chaque workflow est décrit comme une séquence d’états et d’actions, et le modèle apprend à reproduire cette séquence de manière autonome.
L’approche multi-sources enrichit ce processus. Lors de la construction de systèmes IA qui doivent accéder à des connaissances institutionnelles, des pipelines de collecte automatisée (comme les crawlers web qui parcourent systématiquement des sources documentaires officielles) permettent de constituer des bases de connaissances structurées, en équilibrant données institutionnelles autoritaires et retours d’expérience pratiques [4].
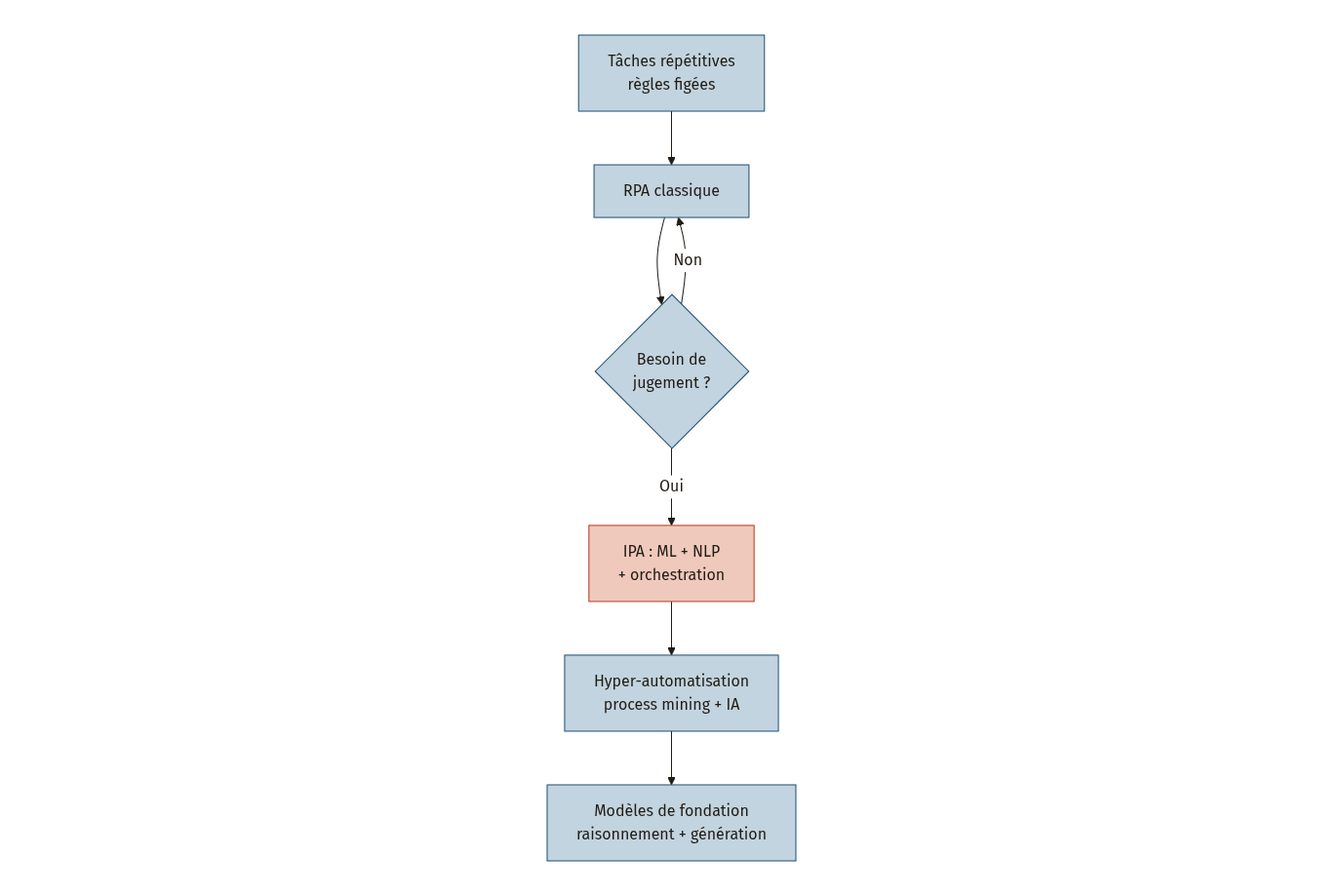
Ce qu’il faut retenir : l’IPA n’est pas le remplacement du RPA, c’est sa couche supérieure. Si vos processus impliquent uniquement des règles simples et des données structurées, le RPA suffit. Dès que le jugement humain entre en jeu, l’IPA devient pertinente.
Cartographier les processus candidats à l’automatisation intelligente
Avant de parler d’outils ou d’architecture, la question cruciale est : quels processus méritent d’être traités par l’IPA ? L’automatisation intelligente a un coût (infrastructure, données, compétences, temps de mise en œuvre). Déployer l’IA là où elle n’apporte rien est le premier échec à éviter.
La cartographie prospective le long de la chaîne de valeur
Le prospective sensemaking (construction collective de sens orientée vers l’avenir) offre une méthode structurée pour cette étape. Concrètement, il s’agit de réunir les parties prenantes et de systématiquement cartographier les cas d’usage potentiels de la collaboration humain-IA le long de la chaîne de valeur de l’organisation [5]. Ce travail de prospective permet d’identifier, avant tout développement technique, où l’IA peut réellement créer de la valeur et où elle constituerait une complication inutile.
Le retour d’expérience d’une entreprise ayant adopté cette approche montre que le mapping systématique des cas d’usage le long de la chaîne de valeur, combiné à l’analyse des tâches de groupe, permet une compréhension structurée du rôle potentiel de l’IA et souligne l’importance de la prospective stratégique lors de l’intégration de l’IA dans les processus organisationnels [5].
L’Enterprise AI Canvas : un cadre structuré
Pour passer de l’idée à l’action, l’Enterprise AI Canvas propose un canevas d’analyse structuré. Ce cadre aide les organisations à identifier les cas d’usage où l’intelligence artificielle peut créer de la valeur, à déterminer les décisions qui peuvent être supportées ou exécutées automatiquement, et à préparer la transformation organisationnelle nécessaire pour intégrer les systèmes d’IA dans la main-d’œuvre humaine [6]. L’intérêt de ce cadre est qu’il force à articuler trois dimensions simultanément : la valeur métier, la faisabilité technique et l’impact organisationnel.
Les modèles multi-étapes pour les workflows complexes
Pour les processus qui impliquent plusieurs étapes de raisonnement, les modèles d’action multi-étapes (MSAM) ont été conçus spécifiquement pour l’adoption de l’IA en entreprise. Les résultats publiés montrent des scores de raisonnement moyen de 88,5 % et une précision de traitement multimodal (lecture et écriture de données sous différentes formes) de 95,9 %, tout en réduisant l’effort humain de 91 % à 97 % selon le profil utilisateur [7]. Concrètement, des processus impliquant la lecture de documents multiples, la comparaison d’informations et la synthèse de résultats peuvent désormais être modélisés et partiellement automatisés.
Adapter l’analyse à votre contexte
La cartographie des candidats à l’IPA varie considérablement selon le secteur et la taille de l’organisation :
- Dans les PME, l’IA est souvent perçue comme réservée aux grandes entreprises, mais elle constitue un levier de croissance stratégique accessible, à condition de cibler les processus à fort impact et à faible complexité de déploiement en premier [8].
- Dans les ONG et le secteur à but non lucratif, les cas d’usage typiques incluent l’automatisation de la comptabilité, la gestion des bénévoles, le traitement des dons et la communication, mais les défis spécifiques (ressources limitées, sensibilité des données des bénéficiaires) nécessitent une cartographie adaptée [9].
- Le long de la chaîne de valeur, les opportunités varient du back-office (traitement de factures, conformité) au front-office (service client, personnalisation) en passant par les opérations centrales (logistique, contrôle qualité) [5].
Ce qu’il faut retenir : ne lancez jamais un projet d’IPA parce que « c’est la tendance ». Commencez par cartographier vos processus réels, évaluez où le jugement humain est réellement nécessaire (et où il ne l’est pas), et priorisez les flux où l’automatisation intelligente apporte un gain mesurable.
Évaluer votre maturité avant d’acheter le moindre outil
L’erreur la plus coûteuse dans un projet d’IPA n’est pas de choisir le mauvais outil, c’est de sous-estimer les lacunes de l’organisation en matière de données, de compétences et de gouvernance. Avant de déployer quoi que ce soit, un diagnostic honnête de votre niveau de maturité est indispensable.
Automatisation de process : l'approche
Comment je le conçois concrètement : étapes, livrables et garde-fous.
Le modèle de maturité centré sur l’humain (HCAI-MM)
Le Human-Centered AI Maturity Model part du principe que la maturité en IA ne se mesure pas seulement à la sophistication technologique, mais à la capacité de l’organisation à intégrer l’IA de manière éthique, efficace et centrée sur l’humain [10]. Ce modèle évalue plusieurs dimensions : la conception organisationnelle (les processus de prise de décision sont-ils structurés pour accompagner l’IA ?), l’intégration de l’IA dans la stratégie (les initiatives IA sont-elles alignées sur les objectifs métier ?), et l’impact sur les indicateurs de performance [10].
Une organisation qui déploie l’IA sans restructurer ses processus de décision et ses flux d’information risque de créer un système sophistiqué que personne n’utilise ou ne comprend.
Les cadres de préparation : plusieurs modèles convergent
Plusieurs frameworks de préparation convergent vers le même constat : l’adoption de l’IA exige une évaluation multidimensionnelle qui va bien au-delà de la simple disponibilité technologique [11]. Le modèle de préparation de Grobbelaar identifie les dimensions organisationnelles clés, l’étude de Jöhnk et al. sur les facteurs de préparation organisationnelle met en lumière les freins culturels et structurels, et le cadre de Holmström relie directement la préparation IA à la transformation digitale globale [11]. L’ensemble de ces travaux, synthétisés dans une revue multidisciplinaire, confirme que les obstacles à l’adoption de l’IA ne sont pas principalement techniques : ils sont organisationnels, culturels et liés aux compétences [11].
Le cadre de trois phases : tactique, stratégique, transformationnel
Le framework de maturité IA et agentique décrit dans GenAI on Google Cloud distingue trois phases d’évolution organisationnelle [12] :
| Phase | Caractéristiques | Valeur métier |
|---|---|---|
| Tactique | Expérimentation isolée, projets pilotes, sensibilisation | Réduite, ponctuelle |
| Stratégique | Connexion entre équipes, standardisation, compétences techniques établies | Croissante, mesurable |
| Transformationnelle | Intégration à l’échelle de l’entreprise, innovation démocratisée | Exponentielle |
La transition d’une phase à l’autre débloque une valeur exponentielle, pas linéaire [12]. Le passage de la phase stratégique à la phase transformationnelle se caractérise par la démocratisation de l’innovation : chaque département est capable de concevoir et déployer ses propres solutions IA.
Les compétences : le facteur déterminant
La technologie ne suffit pas. Les personnes et les compétences sont systématiquement identifiées comme des déterminants critiques de la maturité IA : littératie IA chez les managers, disponibilité de talents analytiques, collaboration interfonctionnelle entre rôles techniques et métier [13]. La maturité IA ne reflète pas seulement l’expertise technique, mais aussi la capacité de l’organisation à interpréter, faire confiance et agir sur les résultats issus de l’IA [13].
Le cadre de compétences IA et données (AI & Data Acumen) structure ce besoin en quatre domaines et quatre niveaux cognitifs [14] :
- Auto-efficacité : reconnaître l’impact de l’IA sur l’identité, l’autonomie et le sens au travail, et concevoir des plans qui préservent la dignité humaine.
- Littératie des données : comprendre comment les données alimentent les modèles.
- Compétences analytiques : savoir évaluer, interpréter et critiquer les résultats de l’IA.
- Création : concevoir des solutions IA adaptées à un problème métier.
Ces compétences se développent sur un parcours structuré qui passe du fondamental (se souvenir et comprendre) à l’expert (créer et concevoir) [14]. Un séminaire d’une journée ne suffit pas.
La maturité spécifique au contexte
Un index d’adoption de l’IA spécifiquement conçu pour les pays du Conseil de coopération du Golfe (GCC) montre qu’il n’existe pas de modèle universel de maturité [15]. L’infrastructure technique, l’environnement de gouvernance, la dynamique de la main-d’œuvre et les normes socioculturelles varient d’un contexte à l’autre. L’index proposé sert d’outil de diagnostic et de benchmarking, permettant d’identifier précisément les lacunes d’adoption et de guider l’allocation stratégique des ressources [15]. Concrètement, une entreprise du CAC 40 et une PME marocaine n’ont pas besoin du même chemin de maturité.
L’infrastructure de données, socle invisible
La maturité organisationnelle inclut une dimension souvent sous-estimée : l’infrastructure de données. Les plateformes analytiques, l’infrastructure cloud, l’intégration des systèmes et les capacités de déploiement de modèles constituent le socle technique de la maturité IA [13]. Mais la sophistication technologique seule ne garantit pas la maturité : la technologie doit être intégrée dans les routines organisationnelles pour générer de la valeur [13].
Ce qu’il faut retenir : évaluez votre maturité sur quatre axes (organisation, compétences, données, gouvernance) avant de sélectionner un outil. Un diagnostic superficiel qui se limite à « avons-nous assez de GPU ? » conduit à des déploiements avortés.
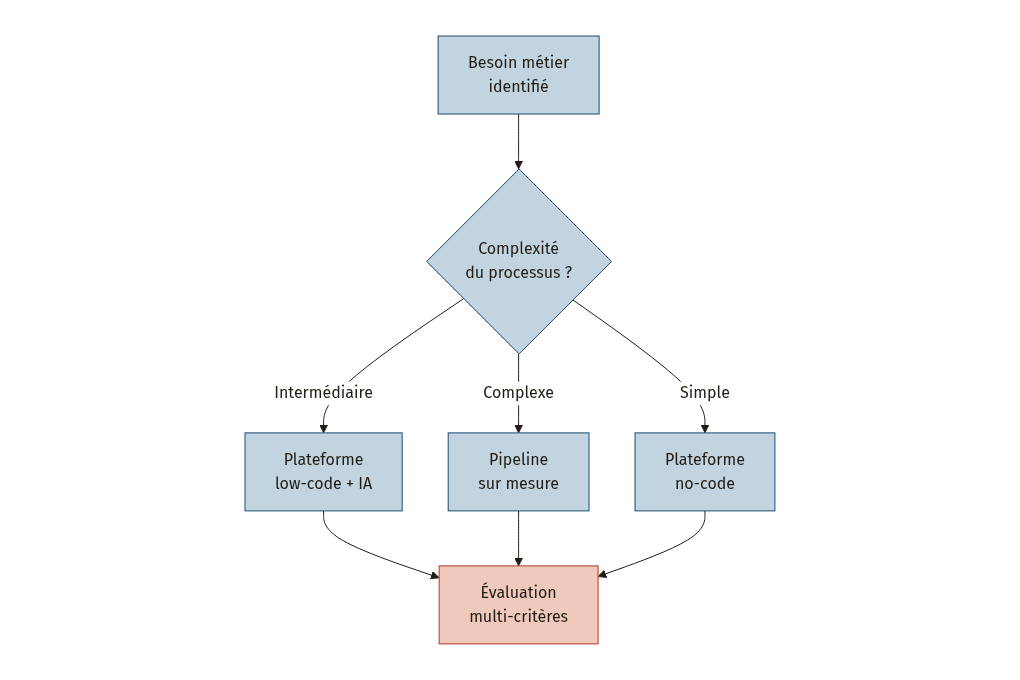
Choisir l’architecture et les briques technologiques
Une fois les processus candidats identifiés et la maturité évaluée, vient le choix des outils et de l’architecture. Ce choix dépend de trois variables : la complexité du processus, les compétences disponibles en interne, et les contraintes de scalabilité.
L’approche no-code/low-code : démocratiser l’automatisation
Les plateformes no-code et low-code permettent de concevoir des flux d’automatisation sans écrire de code, ou avec un minimum de code, via des interfaces visuelles de type glisser-déposer. Elles ouvrent l’accès à l’automatisation à des développeurs « citoyens » (personnes métier sans formation en programmation), capables de créer et maintenir leurs propres workflows [16].
Le cas n8n illustre cette approche. L’étude d’efficacité de l’automatisation de flux de travail avec n8n démontre des gains concrets de productivité mesurés dans un environnement de petite entreprise : service client, marketing et gestion opérationnelle [17]. La plateforme permet de connecter des dizaines d’applications entre elles (CRM, tableurs, messageries, bases de données) et de déclencher des actions automatisées sans intervention humaine. L’étude souligne toutefois les limites de scalabilité des plateformes no-code dans les déploiements de grande envergure, suggérant des approches hybrides pour les environnements d’entreprise complexes [17].
Le cas DIZEST montre comment une méthodologie low-code peut être appliquée au développement de systèmes IA complexes. Son architecture modulaire résout les défis d’intégration, de rigidité structurelle et de goulets d’étranglement de performance qui freinent les systèmes traditionnels [18].
L’interaction entre IA et low-code va dans les deux sens. Les outils comme Copilot et ChatGPT réduisent le besoin de mémoriser de vastes API, tandis que les outils visuels abstraient la programmation mais peinent à offrir un accès facile à des API complexes [16]. La combinaison des deux approches constitue la voie la plus prometteuse.
Critères d’évaluation d’une plateforme
Le framework structuré d’évaluation des plateformes low-code identifie cinq critères pour guider le choix [19] :
- Facilité d’adoption : courbe d’apprentissage, documentation, support communautaire.
- Intégration : connecteurs avec les systèmes existants (ERP, CRM, bases de données).
- Scalabilité : capacité à monter en charge sans réécriture.
- Sécurité et conformité : contrôle d’accès basé sur les rôles, intégration SSO (authentification unique), standards de chiffrement, détection de menaces, gestion du cycle de vie applicatif [19].
- Automatisation IA intégrée : le degré auquel la plateforme intègre des capacités d’IA générative et analytique dans les flux de travail opérationnels [19].
L’infrastructure technique : du stockage à l’accélération matérielle
Pour les projets d’IPA qui impliquent le déploiement de modèles d’IA à grande échelle, l’infrastructure sous-jacente devient critique.
L’orchestration sur Kubernetes (plateforme open source de gestion de conteneurs permettant de déployer et scaler des applications) permet de gérer les modèles de langage en production avec scaling automatique, gestion des versions et tolérance aux pannes. L’ouvrage de référence sur les modèles génératifs sur Kubernetes détaille les options de stockage pour l’entraînement distribué [20] :
| Solution | Accès | Performance | Complexité opérationnelle | Idéal pour |
|---|---|---|---|---|
| Stockage fichier cloud (EFS, Filestore, Azure Files) | Multiples | Cohérente, scaling auto | Faible | Simplicité opérationnelle |
| Stockage objet (S3, GCS, MinIO) | API | Très haute scalabilité | Moyenne | Jeux de données volumineux |
| NVMe local | Single node | Microsecondes, multi-Go/s | Élevée | Staging de données pour I/O maximal |
| NFS | Multiples | Bonne en séquentiel | Faible | Déploiements on-premises existants |
| Systèmes distribués (Ceph, GlusterFS) | Multiples | Haut débit horizontal | Élevée | Plateformes à grande échelle [20] |
Le choix entre GPU (unités de traitement graphique, optimisées pour le parallélisme) et TPU (unités de traitement tensoriel, conçues par Google pour l’IA) dépend du type de goulot d’étranglement rencontré [12] :
- Goulot mémoire : le modèle ne tient pas dans la mémoire de l’appareil. Les GPU offrent une optimisation par appareil, les TPU permettent la distribution sur des pods à haute interconnexion.
- Goulot calcul : l’appareil est utilisé à 100 %. Les GPU sont idéaux pour l’itération rapide, les TPU pour les coûts optimisés à grande échelle.
- Goulot réseau : la synchronisation des gradients entre appareils freine l’entraînement. Les GPU conviennent aux clusters mono-nœud, les TPU à l’entraînement distribué sur des centaines de puces [12].
LLMOps : opérationnaliser les modèles de langage
Le passage des LLM de l’expérimentation à la production requiert une discipline opérationnelle spécifique, le LLMOps, qui diffère significativement du MLOps classique (la discipline d’opérationnalisation des modèles d’apprentissage automatique) [21] :
| Dimension | ML classique | LLMOps |
|---|---|---|
| Adaptation au domaine | Fine-tuning complet, abordable | Fine-tuning coûteux : on préfère RAG, prompt engineering, knowledge graphs |
| Évaluation | Facile, discriminative | Extrêmement difficile, générative, espace de probabilité non borné |
| Robustesse | Modèle stable en production | Comportement changeant selon les interactions, surveillance d’alignement nécessaire |
| Sécurité | Sécurisé | Très vulnérable, nécessite un framework DataSecOps [21] |
L’orchestration de multiples API, la garantie de la réactivité de l’interface et la manipulation efficace de données en temps réel constituent des défis techniques majeurs [22]. Le système IDEIA, conçu pour l’idéation éditoriale dans le journalisme numérique, illustre ces défis : un backend en Node.js, un frontend en React et des pratiques CI/CD (intégration et livraison continues) automatisées permettent de coordonner plusieurs appels API simultanés tout en maintenant une interface fluide [22].
RAG : connecter l’IA à vos propres données
Le Retrieval-Augmented Generation (RAG) est la technique qui permet à un modèle de langage de puiser dans vos documents internes pour répondre à des questions spécifiques. Au lieu de se fier uniquement aux connaissances acquises pendant son entraînement, le modèle consulte une base de données vectorielle contenant vos documents, vos procédures et vos politiques, puis génère une réponse contextualisée.
L’approche RAG traditionnelle se heurte à des limites sur des tâches complexes impliquant un raisonnement multi-étapes. Les workflows documentaires agentiques (ADW) combinent le RAG avec des agents autonomes capables de coordonner plusieurs étapes de traitement, depuis l’analyse de contrats jusqu’au traitement des réclamations, en passant par la vérification de conformité [23].
Ce qu’il faut retenir : ne choisissez pas une plateforme parce qu’elle est « la plus puissante ». Choisissez-la en fonction de la complexité de vos processus, des compétences de vos équipes, et de vos contraintes d’intégration.
Concevoir pour la collaboration humain-IA, pas le remplacement
L’IPA la plus performante ne remplace pas l’humain : elle redéfinit son rôle. Concevoir un système d’automatisation intelligente comme un substitut du travail humain est non seulement un choix éthique discutable, mais aussi un choix technique risqué.
Les systèmes cognitifs conjoints humain-IA
Le cadre des systèmes cognitifs conjoints humain-IA (HAIJCS) propose de repenser fondamentalement l’interaction entre l’humain et la machine [24]. Contrairement aux paradigmes d’interaction traditionnels, qui sont unidirectionnels (l’humain donne un ordre, la machine exécute), le HAIJCS promeut une interaction bidirectionnelle avec des responsabilités partagées entre l’humain et le système [24].
L’exemple des véhicules autonomes illustre ce passage : le système ne se contente pas de suivre des instructions, il partage l’intentionnalité avec le conducteur. Ce dernier n’est plus dans un rôle de surveillance insoutenable, mais dans un rôle d’agence collaborative [24].
L’intégrité du rôle humain
Préserver l’identité, les relations humaines, l’éthique et le sens au travail dans un environnement de plus en plus infusé d’IA est une préoccupation fondamentale [14]. Cela passe par des mesures concrètes : former les équipes à reconnaître les aspects de leur identité et de leurs valeurs affectés par l’IA, leur donner les outils pour maintenir un fort sens de soi et des relations humaines dans un monde enrichi d’IA, et évaluer les effets des systèmes IA sur la perception de l’estime de soi, du but et de l’autonomie [14].
La sécurité dans les environnements industriels
Dans les contextes industriels, les enjeux de sécurité sont concrets et immédiats. L’analyse de l’opérateur humain dans le contrôle des processus a une longue histoire : depuis les premières études sur le rôle de l’opérateur dans les systèmes de contrôle de processus, la recherche a systématiquement montré que la collaboration humain-machine nécessite une conception rigoureuse des niveaux d’intégrité de sécurité (SIL, Safety Integrity Level) et des couches d’analyse de protection [25]. L’Union européenne a formalisé cette préoccupation dans une prospective sur les risques émergents pour la sécurité et la santé au travail liés aux technologies de l’information d’ici 2025, soulignant la nécessité de planifier l’intégration de l’IA avec une attention portée aux risques professionnels [25]. La programmation d’équipes humain-robot dans des cellules de travail collaboratif illustre les défis pratiques de cette cohabitation [25].
La sécurité des agents IA en entreprise
Le benchmark STWebAgentBench évalue la gestion des comportements non sûrs des agents IA dans des environnements d’entreprise, avec un système de supervision humaine et une hiérarchie basée sur les politiques [26]. Ce benchmark introduit la métrique « Completion under Policy » (CuP), qui mesure la conformité des agents aux politiques organisationnelles, utilisateur et spécifiques à la tâche [26].
Le benchmark WorkArena se concentre sur les tâches couramment exécutées dans les environnements de service d’entreprise (la plateforme ServiceNow), offrant un cadre d’évaluation réaliste pour les agents IA dans des scénarios opérationnels concrets [26].
La réduction de l’effort humain : des chiffres concrets
Les modèles MSAM démontrent des réductions d’effort significatives : les généralistes rapportent une réduction de 97 % de leur charge de travail, les observateurs de 95 %, et les spécialistes de 91 % [7]. Ces chiffres ne signifient pas que l’humain disparaît : ils signifient que l’humain passe de l’exécution à la supervision, de la saisie à l’analyse, de la répétition à la création.
Ce qu’il faut retenir : l’IPA ne doit pas éliminer le jugement humain, elle doit le concentrer là où il a le plus de valeur. Concevez vos systèmes avec l’humain dans la boucle de décision, pas en périphérie.
Gouvernance, sécurité et conformité dès le premier jour
La gouvernance n’est pas un frein à l’innovation : c’est ce qui rend l’IPA déployable en production et pérenne. La négliger conduit à des systèmes opaques, vulnérables et potentiellement illégaux.
Un besoin en automatisation de process ?
Configurez votre projet et recevez un devis clair sous 24h, sans engagement.
L’audit et la traçabilité des actions
Le protocole SMCP (Secure Model Context Protocol) fournit un cadre concret pour la gouvernance des agents IA. Chaque entrée dans le journal d’audit peut être reliée à la requête d’origine et à la réponse résultante, garantissant une chaîne de traçabilité complète et vérifiable pour les opérations sensibles [27]. En imposant des enregistrements d’audit explicites, structurés et inviolables pour tous les événements liés à la sécurité, le SMCP fournit une prise de décision digne de confiance, tant dans les flux de travail automatisés que dans ceux impliquant un humain dans la boucle [27].
Le processus fonctionne ainsi : l’utilisateur et les outils s’authentifient mutuellement, les politiques de sécurité sont appliquées, les accès sont contrôlés sur la base des capacités (ce que l’agent est autorisé à faire), et chaque action est journalisée de manière inviolable [27].
Les compétences contractuelles pour les agents IA
Le framework GovernSpec structure la conception des agents IA d’entreprise autour de « compétences contractuelles » : des spécifications formelles qui définissent ce qu’un agent a le droit de faire, dans quel contexte, avec quelles limites et quelles responsabilités [28]. Ce cadre traite honnêtement ses propres limites : les jugements croisés et l’agrégation de deux juges réduisent le biais d’auto-évaluation, mais ne remplacent pas la revue humaine experte [28]. Les résultats décrivent le comportement des modèles testés dans des conditions API spécifiques, et les versions ultérieures peuvent différer [28].
La sécurité face aux attaques
Les agents IA sont vulnérables à des attaques spécifiques, notamment les « jailbreaks » (tentatives de contournement des garde-fous de sécurité par des instructions malveillantes). Le benchmark HarmBench fournit un cadre d’évaluation standardisé pour le red teaming automatisé (tests d’intrusion systématiques) et la robustesse des refus [29].
À une échelle plus large, le champ émergent de l’IA agentique et de la cybersécurité identifie des défis spécifiques aux systèmes qui raisonnent, planifient, utilisent la mémoire et appellent des outils dans le cadre de tâches étendues [30]. Ces systèmes multi-agents multiplient les surfaces d’attaque par leur nature même.
La gouvernance des données sensibles
Les journaux d’incident et les documents de politique interne contiennent souvent des informations sensibles. Leur intégration avec des API de modèles externes nécessite des contrôles d’accès robustes et une manipulation sécurisée [31]. L’automatisation de l’analyse des écarts de politique post-incident via l’IA illustre ce dilemme : le système doit accéder à des données sensibles pour fonctionner, mais cette accès même crée des risques qui appellent une gouvernance renforcée des données [31].
Les critères de sécurité à évaluer dans le choix d’une plateforme incluent le contrôle d’accès basé sur les rôles, les fonctionnalités de conformité (journaux d’audit, protection des données), l’architecture de sécurité (chiffrement, protocoles de communication, détection de menaces) et la gestion du cycle de vie applicatif [19].
Ce qu’il faut retenir : intégrez la gouvernance dans votre architecture dès le premier sprint, pas après le premier incident de sécurité. Un agent IA sans journal d’audit, sans politique d’accès et sans mécanisme de conformité est un risque juridique et opérationnel.
Du pilote au déploiement industriel
Le passage de la preuve de concept au déploiement à l’échelle est le moment où la majorité des projets d’IPA échouent. Le système fonctionne en démo, mais pas en production. Voici un cadre d’itération réaliste.
Feuille de route produit intégrant l’IA
L’intégration des initiatives IA dans la feuille de route produit et la gestion des dépendances est une compétence clé [32]. Chaque initiative d’IPA doit être traitée comme un élément du roadmap produit, avec ses priorités, ses dépendances techniques, ses jalons de validation et ses critères de succès mesurables [32]. L’IA n’est pas un projet à part : c’est une couche fonctionnelle qui s’intègre dans le cycle de développement existant.
L’évaluation continue des systèmes
Le framework ARES (Automated Evaluation Framework for Retrieval-Augmented Generation Systems) offre une méthode pour évaluer automatiquement les performances des systèmes RAG en production [33]. ARES évalue trois dimensions : la pertinence du contexte récupéré (le système a-t-il trouvé les bons documents ?), la fidélité de la réponse au contexte (la réponse reflète-t-elle les documents trouvés ?), et la pertinence de la réponse par rapport à la question [33]. Ce type d’évaluation automatisée permet de surveiller la qualité des systèmes IPA en continu, sans dépendre exclusivement d’évaluations manuelles coûteuses.
Scaling dynamique de l’infrastructure
En production, la demande varie. Les pics d’utilisation (fin de mois, saisonnalité, crises) nécessitent un scaling dynamique des ressources. L’approche proposée pour les charges de travail IA sur Oracle Exadata illustre cette logique : le système tente de se connecter à l’infrastructure cloud réelle et bascule automatiquement en mode simulation pour les environnements de test [34]. L’élasticité de l’infrastructure cloud permet d’augmenter la puissance pendant les heures de pointe et de la réduire pour économiser les coûts pendant les creux [34].
Équipes interfonctionnelles
La complexité des infrastructures d’IA modernes (clusters d’entraînement distribué, parallélisme de modèles, jeux de données massifs, intégration continue des mises à jour) exige des équipes interfonctionnelles capables de gérer à la fois la recherche et l’ingénierie [35]. La frontière entre ingénieur et chercheur en IA s’estompe : les chercheurs sont attendus comme des ingénieurs en pratique, et les ingénieurs contribuent des idées qui orientent la recherche [35]. Recruter pour l’un sans disposer de l’autre crée un goulot d’étranglement organisationnel.
Évolution vers les systèmes matures
L’évolution vers les systèmes IPA matures passe par plusieurs stades [23] :
| Stade | Capacité | Limites |
|---|---|---|
| RAG traditionnel | Question-réponse simple | Mauvaise compréhension contextuelle |
| RAG agentique | Raisonnement multi-étapes, collaboration entre agents | Complexité de coordination |
| Workflows documentaires agentiques (ADW) | Automatisation bout-en-bout, intelligence spécifique au domaine | Surcoût en ressources, standardisation nécessaire [23] |
Les ADW représentent le stade le plus avancé : ils automatisent des processus complets comme la revue de contrats, le traitement de factures ou l’analyse de sinistres, en combinant récupération d’information, raisonnement et action [23].
Le piège de la démo : ce que la production change
Un système qui fonctionne sur 10 documents de démo ne fonctionnera pas nécessairement sur 10 000 documents en production. Les limites de l’évaluation automatisée et des environnements simulés sont documentées : les tâches restent synthétiques et ne doivent pas être généralisées à tous les flux de travail d’entreprise [28]. Les systèmes d’entreprise réels incluent des états, des permissions, des journaux d’audit, de la concurrence, des tentatives de reconnexion et des échecs partiels qui peuvent modifier le comportement [28].
Ce qu’il faut retenir : déployez par itérations courtes avec des critères de succès mesurés. Évaluez automatiquement, scalez dynamiquement, et ne généralisez jamais les résultats d’un pilote sans les confronter aux contraintes de la production réelle.
Sources
- [1] From Robotic Process Automation to Intelligent Process Automation: Emerging Trends · preprint · arXiv:2007.13257
- [2] Hyper-automation-The next peripheral for automation in IT industries · preprint · arXiv:2305.11896
- [3] Automating the Enterprise with Foundation Models · preprint · arXiv:2405.03710
- [4] Large Language Models for Assisting American College Applications · preprint · arXiv:2602.15850
- [5] Use Cases for Prospective Sensemaking of Human-AI-Collaboration · preprint · arXiv:2408.10812
- [6] Enterprise AI Canvas — Integrating Artificial Intelligence into Business · preprint · arXiv:2009.11190
- [7] Designing Multi-Step Action Models for Enterprise AI Adoption · preprint · arXiv:2403.14645
- [8] Leveraging Artificial Intelligence as a Strategic Growth Catalyst for Small and Medium-sized Enterprises · preprint · arXiv:2509.14532
- [9] AI Adoption in NGOs: A Systematic Literature Review · preprint · arXiv:2510.15509
- [10] Human-Centered AI Maturity Model (HCAI-MM): An Organizational Design Perspective · preprint · arXiv:2512.14977
- [11] From Challenge to Change: Design Principles for AI Transformations · preprint · arXiv:2512.05533
- [12] GenAI on Google Cloud Enterprise Generative AI Systems and Agents · livre · Amazon
- [13] Artificial Intelligence (AI) Maturity in Small and Medium-Sized Enterprises: A Framework of Internalized and Ecosystem-Embedded Capabilities · preprint · arXiv:2603.08728
- [14] AI & Data Competencies: Scaffolding holistic AI literacy in Higher Education · preprint · arXiv:2510.24783
- [15] From Vision to Validation: A Theory- and Data-Driven Construction of a GCC-Specific AI Adoption Index · preprint · arXiv:2509.05474
- [16] AI for Low-Code for AI · preprint · arXiv:2305.20015
- [17] Evaluating Workflow Automation Efficiency Using n8n: A Small-Scale Business Case Study · preprint · arXiv:2602.01311
- [18] A Low-Code Methodology for Developing AI Kiosks: a Case Study with the DIZEST Platform · SunMin Moon et al. · 2025 · preprint · arXiv:2511.17853
- [19] A Structured Evaluation Framework for Low-Code Platform Selection: A Multi-Criteria Decision Model for Enterprise Digital Transformation · preprint · arXiv:2510.18590
- [20] Generative AI on Kubernetes Operationalizing Large Language Models · livre · Amazon
- [21] LLMOps Managing Large Language Models in Production · livre · Amazon
- [22] IDEIA: A Generative AI-Based System for Real-Time Editorial Ideation in Digital Journalism · preprint · arXiv:2506.07278
- [23] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG · Aditi Singh et al. · 2025 · preprint · arXiv:2501.09136
- [24] Applying HCAI in developing effective human-AI teaming: A perspective from human-AI joint cognitive systems · preprint · arXiv:2307.03913
- [25] The Digital Divide in Process Safety: Quantitative Risk Analysis of Human-AI Collaboration · preprint · arXiv:2305.17873
- [26] Large Language Model-Brained GUI Agents: A Survey · preprint · arXiv:2411.18279
- [27] SMCP: Secure Model Context Protocol · preprint · arXiv:2602.01129
- [28] Contractual Skills: A GovernSpec Design Framework for Enterprise AI Agents · preprint · arXiv:2605.22634
- [29] Exploring Jailbreak Attacks on LLMs through Intent Concealment and Diversion · preprint · arXiv:2505.14316
- [30] A Survey of Agentic AI and Cybersecurity Challenges, Opportunities and Use-case Prototypes · Sahaya Jestus Lazer et al. · 2026 · preprint · arXiv:2601.05293
- [31] Automated Post-Incident Policy Gap Analysis via Threat-Informed Evidence Mapping using Large Language Models · preprint · arXiv:2601.03287
- [32] The AI Product Playbook Strategies, Skills, and Frameworks for the AI-Driven Product Manager · livre · Amazon
- [33] ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems · Jon Saad-Falcon et al. · 2023 · preprint · arXiv:2311.09476
- [34] RAG-Driven Generative AI Build MAS-RAG with DualRAG, GraphRAG, multimodal video pipelines, and Oracle Database 23ai · livre · Amazon
- [35] The AI Roles Continuum: Blurring the Boundary Between Research and Engineering · preprint · arXiv:2601.06087


