
Un agent IA qui lit un ticket Jira le matin, interroge votre CRM à midi et met à jour votre ERP avant 18 h, sans recâbler le code entre chaque système : c’est exactement ce que le MCP (Model Context Protocol) rend possible. Le protocole remplace la mosaïque d’intégrations artisanales par un réseau de serveurs standardisés, chacun exposant des actions et des données que tout agent compatible peut brancher à la volée [1]. Voici comment construire le vôtre, de la sélection du premier système à la mise en production sécurisée.
1. MCP en 30 secondes : le seul modèle mental dont vous avez besoin
Le MCP repose sur une architecture client-serveur classique [1][2]. Votre application IA (le host, par exemple Claude Desktop ou votre agent maison) embarque un client MCP. Ce client se connecte à des serveurs MCP, chacun encapsulant un service métier.
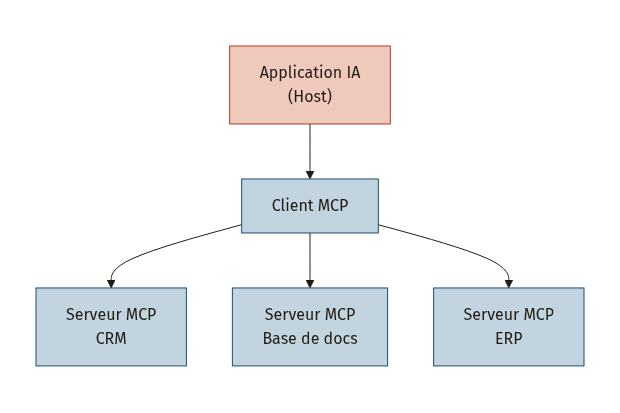
Chaque serveur expose trois primitifs [1][3] :
- Tools (outils) : des actions invocables (créer un ticket, lire un contact, exécuter une requête). Chaque tool porte un nom, une description en langage naturel et un schéma d’entrée JSON, pour que le LLM sache quand et comment l’utiliser.
- Resources (ressources) : des données lisibles par l’agent (fichiers, enregistrements, configurations).
- Prompts : des templates d’instruction réutilisables qui encodent les bonnes pratiques pour accomplir une tâche donnée, comme des modèles de synthèse ou d’analyse [3]. Ils ne contiennent pas de logique exécutive, mais servent de point de départ structuré pour des workflows récurrents.
Avant MCP, connecter M agents à N outils exigeait M×N intégrations sur mesure. MCP réduit cette complexité à M+N [1] : un seul protocole, des connexions universelles. C’est l’analogie « USB-C pour l’IA » popularisée par Anthropic.
Ce qu’il faut retenir pour la suite : vous allez construire un processus (le serveur) qui enveloppe votre service existant et expose ses capacités en tools, resources et prompts. Le LLM se charge de décider lequel appeler et quand.
2. Choisir votre premier terrain : quel système exposer en premier ?
Pas besoin de tout connecter d’un coup. Le premier serveur MCP doit être un quick win qui prouve la valeur du modèle et monte votre équipe en compétence.
Trois critères de sélection
- Valeur métier immédiate. Le système est-il sollicité quotidiennement par vos équipes ou vos agents IA actuels ? Plus il est consulté, plus le gain de l’exposer via MCP est élevé.
- API existante propre. Un serveur MCP est avant tout un enrobage autour d’une API. Si votre système expose déjà une REST ou une GraphQL documentée, le travail est un habillage, pas de la rétro-ingénierie.
- Risque modéré. Pour un premier pilote, évitez les systèmes où un appel erroné aurait des conséquences lourdes (comptabilité, RH sensible, trading). L’idée est d’apprendre sans pression.
Les candidats les plus fréquents
La littérature identifie plusieurs types de serveurs MCP comme bonnes cibles initiales [4] :
| Type de serveur | Ce qu’il expose | Complexité | Idéal pour |
|---|---|---|---|
| Base de connaissances (Knowledge Graph Server) | Recherche d’entités, parcours de relations, requêtes sur graphe | Faible à moyenne | Quick win si vos docs sont déjà indexées |
| Contexte utilisateur (User Context Server) | Profils, préférences, historiques d’interaction | Moyenne | Personnalisation des réponses (attention confidentialité) |
| Intégration outil (Tool Integration Servers) | Opérations CRUD sur CRM, ERP, gestion de projet… | Moyenne à élevée | Cas le plus courant, gain le plus visible |
| IoT / laboratoire | Commandes de capteurs, orchestration d’expériences | Variable | Équipes R&D, laboratoires automatisés [5][6] |
Les secteurs diffèrent dans leurs obstacles. Les équipes Internet se heurtent surtout à l’intégration d’outils externes et à l’optimisation des performances ; les équipes fintech peinent davantage sur la construction de systèmes de réutilisation des connaissances [7]. Identifiez votre blocage principal avant de vous lancer.
→ Action : listez vos 5 systèmes les plus sollicités, notez l’état de leur API (documentée / partielle / absente), et choisissez celui qui combine API propre et forte fréquence d’appel.
3. Assembler le squelette technique : host, serveur, transport
Choisir votre SDK
Deux écosystèmes dominent : Python et TypeScript. Le choix dépend de votre stack existant. Les deux SDK officiels gèrent le protocole pour vous ; vous ne codez que la logique métier.
Intégration d'IA : l'approche
Comment je le conçois concrètement : étapes, livrables et garde-fous.
Choisir le transport
Le protocole MCP supporte deux modes de communication [8] :
| Transport | Fonctionnement | Quand l’utiliser |
|---|---|---|
| stdio | Le serveur tourne en sous-processus du host, communique via les entrées/sorties standard (stdin, stdout) | Développement local, outils en ligne de commande, premier pilote |
| HTTP + SSE | Le serveur expose un endpoint HTTP, le client s’y connecte via des événements en flux continu (Server-Sent Events) | Déploiement distant, multi-clients, architecture réseau |
Pour un premier pilote, stdio est le plus simple : pas de réseau à configurer, pas de certificat à gérer.
La poignée de main (handshake)
Avant tout échange utile, le client et le serveur négocient une session [8] :
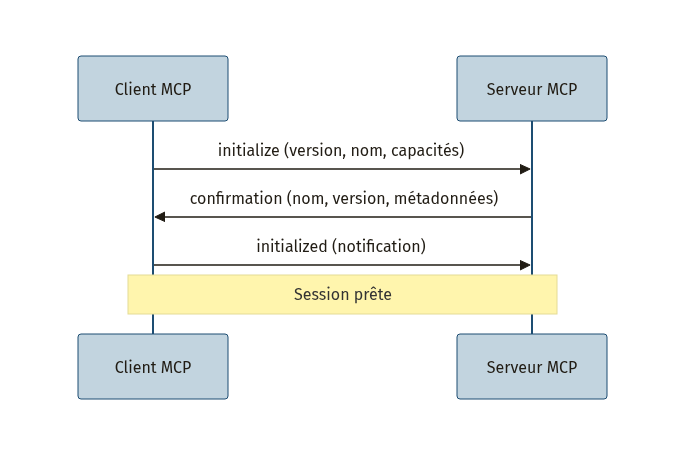
Le client déclare sa version du protocole et ses capacités (par exemple la gestion des notifications). Le serveur répond avec son nom, sa version, des métadonnées et des instructions d’utilisation optionnelles. Une fois la confirmation échangée, la session est ouverte.
Votre premier tool en pratique
Un tool MCP se définit par trois éléments [1] :
- Nom : identifiant unique, en snake_case.
- Description : une phrase en langage naturel. C’est elle que le LLM lit pour décider si ce tool est pertinent. Rédigez-la comme si vous expliquiez l’outil à un collègue.
- Schéma d’entrée : un JSON Schema décrivant les paramètres attendus.
Exemple concret pour un CRM :
Nom : rechercher_contact
Description : "Recherche un contact dans le CRM par nom ou email"
Entrée :
{
"type": "object",
"properties": {
"query": { "type": "string", "description": "Nom ou email" }
},
"required": ["query"]
}
→ Action : installez le SDK, copiez un exemple de tool de la documentation officielle, adaptez le nom et la description à votre premier cas, lancez-le en mode stdio, et appelez-le depuis votre client. Objectif : un échange fonctionnel en moins d’une heure.
4. Passer de la démo au cas métier : concevoir vos tools et resources
La règle d’or : un tool = une action
Chaque tool doit faire une seule chose, avec un schéma d’entrée explicite que le LLM peut raisonner. Si votre action métier est complexe (créer un devis complet, par exemple), décomposez-la en plusieurs tools successifs (rechercher client, calculer prix, soumettre devis). Le LLM orchestre la séquence.
Tools, resources, prompts : quand utiliser quoi ?
| Primitif | Rôle | Exemple concret | Fourni par |
|---|---|---|---|
| Tool | Exécute une action (CRUD, calcul, appel API) | creer_ticket, lire_contact, mettre_a_jour_stock |
Le serveur |
| Resource | Expose des données lisibles sans logique | crm://contacts/{id}, config://app.yaml |
Le serveur |
| Prompt | Fournit un template d’instruction paramétrable | preparer_reunion(contact_id), analyser_incident(ticket_id) |
Le serveur |
Les prompts peuvent référencer des tools ou des resources, mais ils n’exécutent pas de logique eux-mêmes. Ils rendent le comportement de l’agent plus prévisible en encodant les meilleures pratiques pour des scénarios connus [3].
Modéliser VOS opérations concrètes
Prenons un serveur MCP pour un CRM. Voici la décomposition typique :
Tools :
– rechercher_contact (query: string) → liste de contacts
– creer_contact (nom, email, société) → contact créé
– lire_opportunites (contact_id: string) → opportunités liées
Resources :
– crm://contacts/{id} → fiche détaillée d’un contact
– crm://pipeline → état actuel du pipeline de vente
Prompts :
– preparer_reunion (contact_id: string) → génère un briefing structuré à partir du contexte du contact et de ses opportunités en cours
→ Action : pour chaque système que vous exposez, listez d’abord les 3 à 5 actions les plus fréquentes (ce sont vos tools), puis les données qu’un agent aurait besoin de consulter (vos resources), enfin les scénarios récurrents (vos prompts).
5. Sécuriser avant de déployer
Les couches de défense
La sécurité d’un serveur MCP passe par plusieurs niveaux imbriqués [9] :
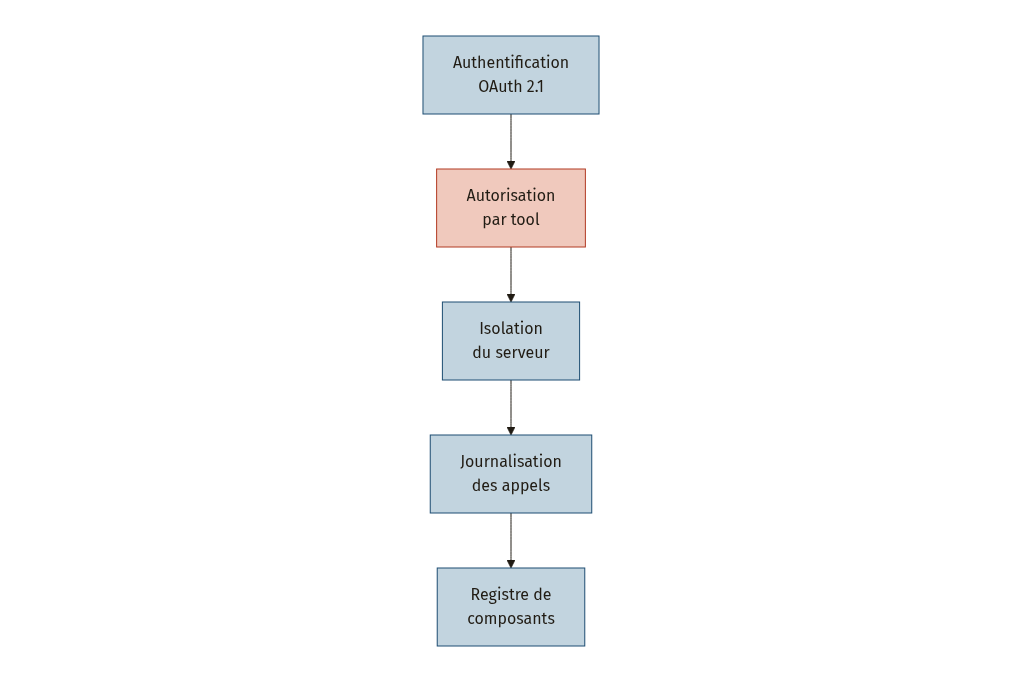
Authentification. Le MCP utilise OAuth 2.1 lorsque les serveurs exigent un accès authentifié [1]. En pratique, le serveur MCP agit comme un serveur de ressources OAuth, protégeant ses tools et resources avec des mécanismes standard. Pour un déploiement AWS, par exemple, on crée un rôle IAM rattaché à l’environnement d’exécution du serveur, ce qui évite de stocker des credentials utilisateur dans le code [8].
Autorisation par tool. Appliquez le moindre privilège : chaque client ne voit que les tools dont il a besoin. Un agent de support client n’a pas d’accès au tool supprimer_compte. C’est la couche la plus critique de l’architecture [9].
Registre de composants de confiance. Le framework SMCP propose un registre centralisé où chaque composant reçoit un code d’identité unique de 32 caractères [10] :
| Composant | Ce que le registre stocke |
|---|---|
| Utilisateur | Code d’identité, profil, rôles, relations organisationnelles, attributs de conformité |
| Agent (host) | Code du modèle, environnement de déploiement, portée fonctionnelle, limites opérationnelles |
| Serveur MCP | Fournisseur, description des capacités exposées, documentation de sécurité |
C’est le modèle à viser si votre organisation exige une traçabilité complète des échanges entre agents et systèmes.
Infrastructure réseau. Une implémentation de référence combine Traefik comme passerelle (routage, authentification forward), CrowdSec pour la détection d’intrusions et le banning comportemental, et un gestionnaire d’interface pour configurer les nouveaux serveurs [11]. La passerelle gère le flux OAuth au nom des serveurs individuels, ce qui simplifie chacun d’entre eux.
Les menaces spécifiques à connaître
La taxonomie MCP-38 recense les vecteurs d’attaque propres au protocole [12]. Un exemple concret : en mode stdio, le serveur communique via les descripteurs de fichiers standards (stdin, stdout). Un processus malveillant co-localisé sous le même compte utilisateur peut injecter des commandes dans le flux MCP ou en lire les données. Les protections incluent le sandboxing du processus serveur, la fermeture systématique des descripteurs inutilisés et la limitation de leur héritage par les sous-processus.
→ Checklist avant déploiement :
– [ ] OAuth 2.1 ou authentification équivalente en place
– [ ] Chaque tool a un scope d’accès défini et restrictif
– [ ] Les credentials ne sont jamais stockés dans le code du serveur
– [ ] Le serveur tourne dans un environnement isolé (container, sandbox)
– [ ] Les appels sont journalisés avec l’identité du client, le tool appelé et le résultat
6. Éviter les pièges : les bugs les plus fréquents en production
L’analyse de plus de 13 500 dépôts GitHub implémentant un serveur MCP révèle un paysage de bugs diversifié en conditions réelles [13]. Voici cinq catégories de problèmes fréquemment rencontrés à surveiller en priorité :
Un besoin en intégration d'IA ?
Configurez votre projet et recevez un devis clair sous 24h, sans engagement.
| Catégorie | Ce qui se passe | Comment l’éviter |
|---|---|---|
| Sérialisation des paramètres | Le serveur reçoit un paramètre dans un format inattendu (string au lieu de nombre, JSON mal formé) et échoue silencieusement | Validez chaque entrée contre le schéma JSON déclaré avant exécution |
| Timeouts non gérés | L’appel au service backend prend trop de temps, le client ne reçoit jamais de réponse, la session se bloque | Définissez des timeouts explicites par tool et renvoyez une erreur structurée |
| Gestion d’état corrompue | Le serveur maintient un état interne entre les appels (connexion BD partagée, cache périmé) qui se corrompt | Concevez vos tools comme des fonctions sans état ; si un état est nécessaire, gérez-le avec des sessions explicites |
| Erreurs de schéma silencieuses | Le tool retourne un résultat non conforme au schéma de sortie déclaré, le LLM interprète mal la réponse | Testez systématiquement la conformité des réponses au schéma attendu |
| Descriptions de tools ambiguës | Le LLM hésite entre deux tools ou choisit le mauvais car les descriptions se chevauchent | Rédigez des descriptions distinctes et spécifiques ; testez les choix du LLM avec des requêtes réalistes |
→ Action : intégrez dès le départ une batterie de tests qui (1) valide les entrées contre le schéma, (2) simule des timeouts, (3) vérifie la conformité des sorties, et (4) teste les choix du LLM avec au moins 10 requêtes représentatives de votre cas d’usage.
7. Passer au scale : monitoring, performance, multi-serveurs
Les repères de performance
Le projet IoT-MCP, qui connecte des LLM à des capteurs physiques via MCP, a mesuré : 205 ms de temps de réponse moyen, une empreinte mémoire de 74 KB au pic, et un taux de succès de 100 % sur 22 types de capteurs et 6 microcontrôleurs [6]. Ce sont des valeurs plancher, obtenues sur un cas simple. En entreprise, avec des appels à des bases volumineuses ou des API tierces, attendez-vous à des latences supérieures.
Les bonnes pratiques d’exploitation
Caching par resource. Si une resource est consultée fréquemment sans changer souvent (liste des produits, organigramme), mettez en cache sa réponse côté serveur avec une durée de vie explicite.
Partitionnement par domaine. Un serveur par domaine métier (CRM, ERP, support, RH) plutôt qu’un monolithe. Cela isole les pannes, simplifie les mises à jour et permet de faire évoluer chaque domaine indépendamment [4].
Monitoring. Journalisez pour chaque appel : le tool invoqué, la latence, le code de retour, l’identité du client. Surveillez les taux d’erreur par tool pour détecter les régressions tôt.
Orchestration multi-agents. Quand plusieurs agents accèdent aux mêmes serveurs MCP, les travaux sur les systèmes multi-agents recommandent des techniques de gestion de contexte partagé : cache de contexte entre agents, coordination par priorité, et filtrage des informations redondantes [4][7].
De un serveur à un écosystème
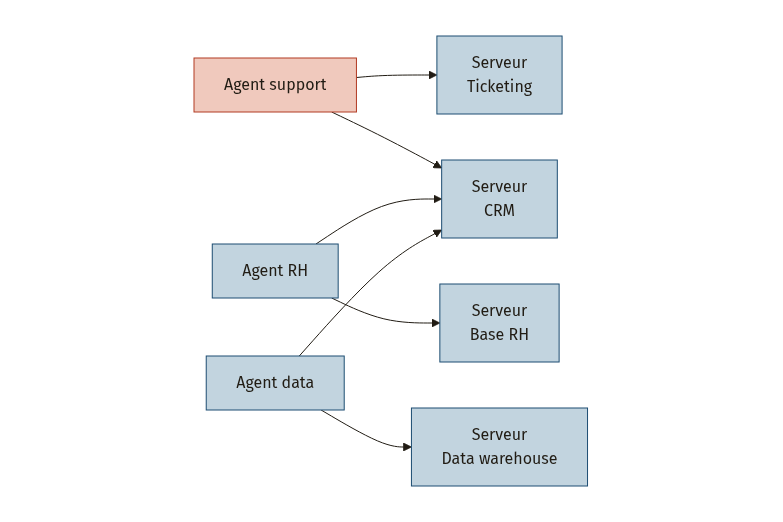
La puissance de MCP apparaît quand vous passez d’un pilote isolé à un réseau : chaque nouvel agent accède à tous les serveurs existants sans code supplémentaire, et chaque nouveau serveur est immédiatement disponible pour tous les agents. C’est l’effet M+N en action [1].
→ Action : une fois votre premier serveur en production, identifiez le deuxième système à exposer, celui qui débloquera le plus de nouveaux cas d’usage pour vos agents existants. Visez un catalogue de 3 à 5 serveurs MCP dans les trois premiers mois. L’objectif n’est pas de tout connecter, mais de constituer progressivement un réseau où chaque nouveau serveur multiplie la valeur de tous les autres.
Sources
- [1] Generative AI on Kubernetes Operationalizing Large Language Models · livre · Amazon
- [2] Beyond Formal Semantics for Capabilities and Skills: Model Context Protocol in Manufacturing · preprint · arXiv:2506.11180
- [3] Hands-On RAG for Production · Ofer Mendelevitch and Forrest Sheng Bao · livre · Amazon
- [4] Advancing Multi-Agent Systems Through Model Context Protocol: Architecture, Implementation, and Applications · preprint · arXiv:2504.21030
- [5] NIMO Controller: a self-driving laboratory orchestrator based on the Model Context Protocol · preprint · arXiv:2605.15227
- [6] IoT-MCP: Bridging LLMs and IoT Systems Through Model Context Protocol · preprint · arXiv:2510.01260
- [7] Understanding How Enterprises Adopt the Model Context Protocol for LLM-Driven Software Engineering · Kehui Chen et al. · 2026 · preprint · arXiv:2606.09182
- [8] Data Engineering with Generative and Agentic AI on AWS · livre · Amazon
- [9] Securing the Model Context Protocol (MCP): Risks, Controls, and Governance · preprint · arXiv:2511.20920
- [10] SMCP: Secure Model Context Protocol · preprint · arXiv:2602.01129
- [11] Simplified and Secure MCP Gateways for Enterprise AI Integration · preprint · arXiv:2504.19997
- [12] MCP-38: A Comprehensive Threat Taxonomy for Model Context Protocol Systems (v1.0) · preprint · arXiv:2603.18063
- [13] Real Faults in Model Context Protocol (MCP) Software: a Comprehensive Taxonomy · preprint · arXiv:2603.05637


